If you’re training or sampling from generative models, typicality is a concept worth understanding. It sheds light on why beam search doesn’t work for autoregressive models of images, audio and video; why you can’t just threshold the likelihood to perform anomaly detection with generative models; and why high-dimensional Gaussians are “soap bubbles”. This post is a summary of my current thoughts on the topic.
First, some context: one of the reasons I’m writing this, is to structure my own thoughts about typicality and the unintuitive behaviour of high-dimensional probability distributions. Most of these thoughts have not been empirically validated, and several are highly speculative and could be wrong. Please bear this in mind when reading, and don’t hesitate to use the comments section to correct me. Another reason is to draw more attention to the concept, as I’ve personally found it extremely useful to gain insight into the behaviour of generative models, and to correct some of my flawed intuitions. I tweeted about typicality a few months ago, but as it turns out, I have a lot more to say on the topic!
As with most of my blog posts, I will assume a degree of familiarity with machine learning. For certain parts, some knowledge of generative modelling is probably useful as well. Section 3 of my previous blog post provides an overview of generative models.
Overview (click to scroll to each section):
- The joys of likelihood
- Motivating examples
- Abstraction and the curse of dimensionality
- Typicality
- Typicality in the wild
- The right level of abstraction
- Closing thoughts
- Acknowledgements
- References
The joys of likelihood
When it comes to generative modelling, my personal preference for the likelihood-based paradigm is no secret (my recent foray into adversarial methods for text-to-speech notwithstanding). While there are many other ways to build and train models (e.g. using adversarial networks, score matching, optimal transport, quantile regression, … see my previous blog post for an overview), there is something intellectually pleasing about the simplicity of maximum likelihood training: the model explicitly parameterises a probability distribution, and we fit the parameters of that distribution so it is able to explain the observed data as well as possible (i.e., assigns to it the highest possible likelihood).
It turns out that this is far from the whole story, and ‘higher likelihood’ doesn’t always mean better in a way that we actually care about. In fact, the way likelihood behaves in relation to the quality of a model as measured by humans (e.g. by inspecting samples) can be deeply unintuitive. This has been well-known in the machine learning community for some time, and Theis et al.’s A note on the evaluation of generative models1 does an excellent job of demonstrating this with clever thought experiments and concrete examples. In what follows, I will expound on what I think is going on when likelihoods disagree with our intuitions.
One particular way in which a higher likelihood can correspond to a worse model is through overfitting on the training set. Because overfitting is ubiquitous in machine learning research, the unintuitive behaviours of likelihood are often incorrectly ascribed to this phenomenon. In this post, I will assume that overfitting is not an issue, and that we are talking about properly regularised models trained on large enough datasets.
Motivating examples
Unfair coin flips

Jessica Yung has a great blog post that demonstrates how even the simplest of probability distributions start behaving in unintuitive ways in higher-dimensional spaces, and she links this to the concept of typicality. I will borrow her example here and expand on it a bit, but I recommend reading the original post.
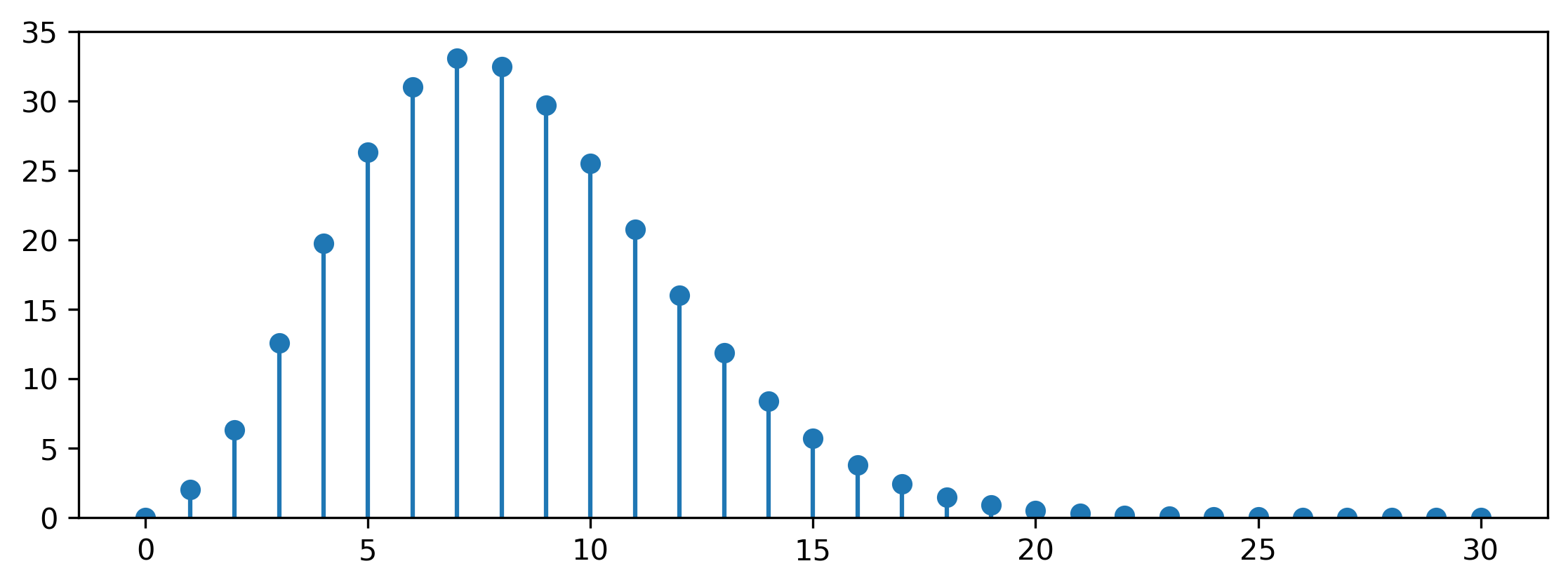
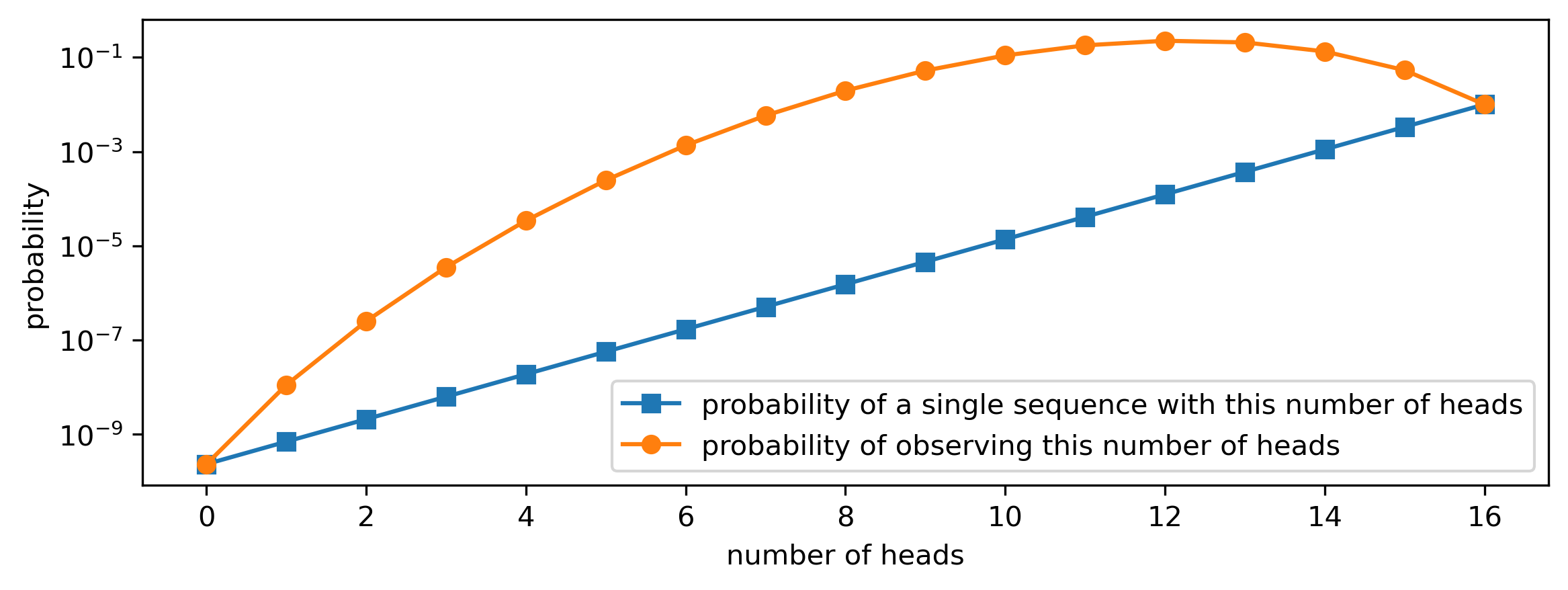
To summarise: suppose you have an unfair coin that lands on heads 3 times out of 4. If you toss this coin 16 times, you would expect to see 12 heads (H) and 4 tails (T) on average. Of course you wouldn’t expect to see exactly 12 heads and 4 tails every time: there’s a pretty good chance you’d see 13 heads and 3 tails, or 11 heads and 5 tails. Seeing 16 heads and no tails would be quite surprising, but it’s not implausible: in fact, it will happen about 1% of the time. Seeing all tails seems like it would be a miracle. Nevertheless, each coin toss is independent, so even this has a non-zero probability of being observed.
When we count the number of heads and tails in the observed sequence, we’re looking at the binomial distribution. We’ve made the implicit assumption that what we care about is the frequency of occurrence of both outcomes, and not the order in which they occur. We’ve made abstraction of the order, and we are effectively treating the sequences as unordered sets, so that HTHHTHHHHTTHHHHH and HHHHHTHTHHHTHTHH are basically the same thing. That is often desirable, but it’s worth being aware of such assumptions, and making them explicit.
If we do not ignore the order, and ask which sequence is the most likely, the answer is ‘all heads’. That may seem surprising at first, because seeing only heads is a relatively rare occurrence. But note that we’re asking a different question here, about the ordered sequences themselves, rather than about their statistics. While the difference is pretty clear here, the implicit assumptions and abstractions that we tend to use in our reasoning are often more subtle.
The table and figure below show how the probability of observing a given number of heads and tails can be found by multiplying the probability of a particular sequence with the number of such sequences. Note that ‘all heads’ has the highest probability out of all sequences (bolded), but there is only a single such sequence. The most likely number of heads we’ll observe is 12 (also bolded): even though each individual sequence with 12 heads is less likely, there are a lot more of them, and this second factor ends up dominating.
| #H | #T | p(sequence) | # sequences | p(#H, #T) |
|---|---|---|---|---|
| 0 | 16 | \(\left(\frac{3}{4}\right)^0 \left(\frac{1}{4}\right)^{16} = 2.33 \cdot 10^{-10}\) | 1 | \(2.33\cdot 10^{-10}\) |
| 1 | 15 | \(\left(\frac{3}{4}\right)^1 \left(\frac{1}{4}\right)^{15} = 6.98 \cdot 10^{-10}\) | 16 | \(1.12\cdot 10^{-8}\) |
| 2 | 14 | \(\left(\frac{3}{4}\right)^2 \left(\frac{1}{4}\right)^{14} = 2.10 \cdot 10^{-9}\) | 120 | \(2.51\cdot 10^{-7}\) |
| 3 | 13 | \(\left(\frac{3}{4}\right)^3 \left(\frac{1}{4}\right)^{13} = 6.29 \cdot 10^{-9}\) | 560 | \(3.52\cdot 10^{-6}\) |
| 4 | 12 | \(\left(\frac{3}{4}\right)^4 \left(\frac{1}{4}\right)^{12} = 1.89 \cdot 10^{-8}\) | 1820 | \(3.43\cdot 10^{-5}\) |
| 5 | 11 | \(\left(\frac{3}{4}\right)^5 \left(\frac{1}{4}\right)^{11} = 5.66 \cdot 10^{-8}\) | 4368 | \(2.47\cdot 10^{-4}\) |
| 6 | 10 | \(\left(\frac{3}{4}\right)^6 \left(\frac{1}{4}\right)^{10} = 1.70 \cdot 10^{-7}\) | 8008 | \(1.36\cdot 10^{-3}\) |
| 7 | 9 | \(\left(\frac{3}{4}\right)^7 \left(\frac{1}{4}\right)^9 = 5.09 \cdot 10^{-7}\) | 11440 | \(5.83\cdot 10^{-3}\) |
| 8 | 8 | \(\left(\frac{3}{4}\right)^8 \left(\frac{1}{4}\right)^8 = 1.53 \cdot 10^{-6}\) | 12870 | \(1.97\cdot 10^{-2}\) |
| 9 | 7 | \(\left(\frac{3}{4}\right)^9 \left(\frac{1}{4}\right)^7 = 4.58 \cdot 10^{-6}\) | 11440 | \(5.24\cdot 10^{-2}\) |
| 10 | 6 | \(\left(\frac{3}{4}\right)^{10} \left(\frac{1}{4}\right)^6 = 1.37 \cdot 10^{-5}\) | 8008 | \(1.10\cdot 10^{-1}\) |
| 11 | 5 | \(\left(\frac{3}{4}\right)^{11} \left(\frac{1}{4}\right)^5 = 4.12 \cdot 10^{-5}\) | 4368 | \(1.80\cdot 10^{-1}\) |
| 12 | 4 | \(\left(\frac{3}{4}\right)^{12} \left(\frac{1}{4}\right)^4 = 1.24 \cdot 10^{-4}\) | 1820 | \(\mathbf{2.25\cdot 10^{-1}}\) |
| 13 | 3 | \(\left(\frac{3}{4}\right)^{13} \left(\frac{1}{4}\right)^3 = 3.71 \cdot 10^{-4}\) | 560 | \(2.08\cdot 10^{-1}\) |
| 14 | 2 | \(\left(\frac{3}{4}\right)^{14} \left(\frac{1}{4}\right)^2 = 1.11 \cdot 10^{-3}\) | 120 | \(1.34\cdot 10^{-1}\) |
| 15 | 1 | \(\left(\frac{3}{4}\right)^{15} \left(\frac{1}{4}\right)^1 = 3.33 \cdot 10^{-3}\) | 16 | \(5.35\cdot 10^{-2}\) |
| 16 | 0 | \(\left(\frac{3}{4}\right)^{16} \left(\frac{1}{4}\right)^0 = \mathbf{1.00 \cdot 10^{-2}}\) | 1 | \(1.00\cdot 10^{-2}\) |
import matplotlib.pyplot as plt
import numpy as np
import scipy.special
h = np.arange(16 + 1)
p_sequence = (3/4)**h * (1/4)**(16 - h)
num_sequences = scipy.special.comb(16, h)
p_heads_count = p_sequence * num_sequences
plt.figure(figsize=(9, 3))
plt.plot(h, p_sequence, 'C0-s',
label='probability of a single sequence with this number of heads')
plt.plot(h, p_heads_count, 'C1-o',
label='probability of observing this number of heads')
plt.yscale('log')
plt.xlabel('number of heads')
plt.ylabel('probability')
plt.legend()
Gaussian soap bubbles

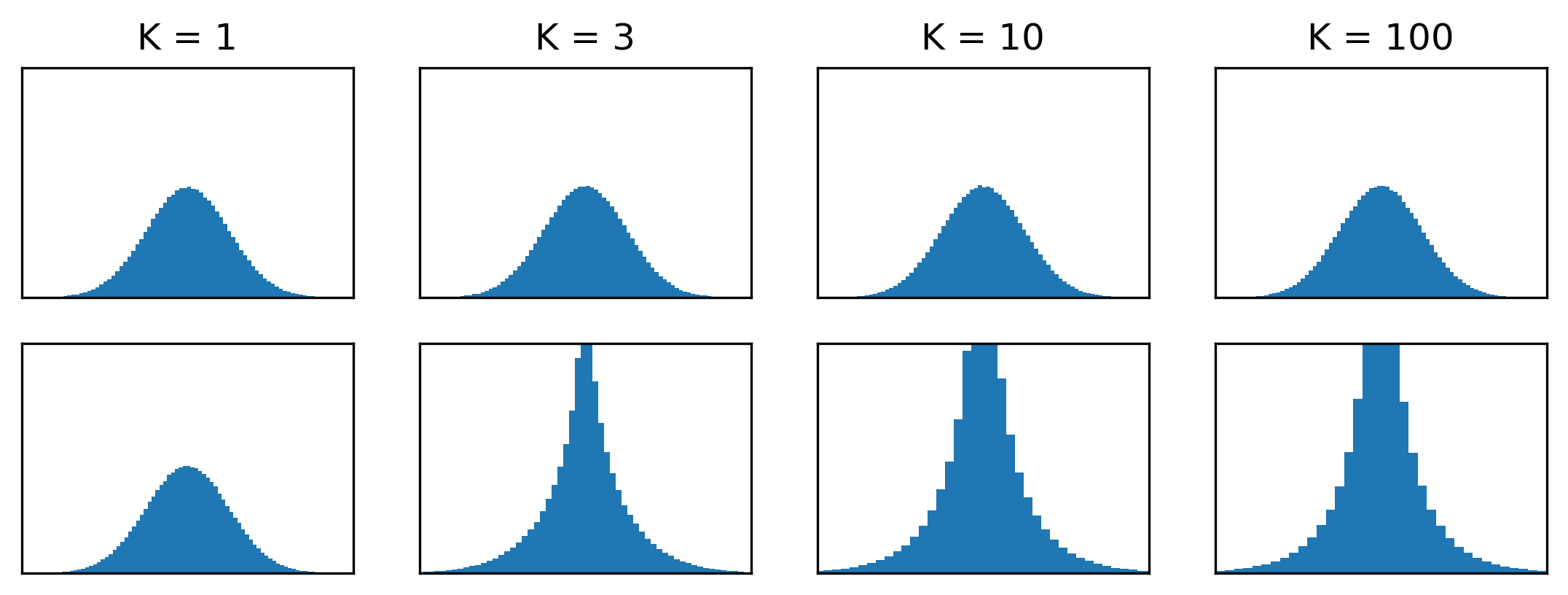
Another excellent blog post about the unintuitive behaviour of high-dimensional probability distributions is Ferenc Huszar’s ‘Gaussian Distributions are Soap Bubbles’. A one-dimensional Gaussian looks like bell curve: a big bump around the mode, with a tail on either side. Clearly, the bulk of the total probability mass is clumped together around the mode. In higher-dimensional spaces, this shape changes completely: the bulk of the probability mass of a spherical Gaussian distribution with unit variance in \(K\) dimensions is concentrated in a thin ‘shell’ at radius \(\sqrt{K}\). This is known as the Gaussian annulus theorem.
For example, if we sample lots of vectors from a 100-dimensional standard Gaussian, and measure their radii, we will find that just over 84% of them are between 9 and 11, and more than 99% are between 8 and 12. Only about 0.2% have a radius smaller than 8!
Ferenc points out an interesting implication: high-dimensional Gaussians are very similar to uniform distributions on the sphere. This clearly isn’t true for the one-dimensional case, but it turns out that’s an exception, not the rule. Stefan Stein also discusses this implication in more detail in a recent blog post.
Where our intuition can go wrong here, is that we might underestimate how quickly a high-dimensional space grows in size as we move further away from the mode. Because of the radial symmetry of the distribution, we tend to think of all points at a given distance from the mode as similar, and we implicitly group them into sets of concentric spheres. This allows us to revert back to reasoning in one dimension, which we are more comfortable with: we think of a high-dimensional Gaussian as a distribution over these sets, rather than over individual points. What we tend to overlook, is that those sets differ wildly in size: as we move away from the mode, they grow larger very quickly. Note that this does not happen at all in 1D!
Abstraction and the curse of dimensionality

The curse of dimensionality is a catch-all term for various phenomena that appear very different and often counterintuitive in high-dimensional spaces. It is used to highlight poor scaling behaviour of ideas and algorithms, where one wouldn’t necessarily expect it. In the context of machine learning, it is usually used in a more narrow sense, to refer to the fact that models of high-dimensional data tend to require very large training datasets to be effective. But the curse of dimensionality manifests itself in many forms, and the unintuitive behaviour of high-dimensional probability distributions is just one of them.
In general, humans have lousy intuitions about high-dimensional spaces. But what exactly is going on when we get things wrong about high-dimensional distributions? In both of the motivating examples, the intuition breaks down in a similar way: if we’re not careful, we might implicitly reason about the probabilities of sets, rather than individual points, without taking into account their relative sizes, and arrive at the wrong answer. This means that we can encounter this issue for both discrete and continuous distributions.
We can generalise this idea of grouping points into sets of similar points, by thinking of it as ‘abstraction’: rather than treating each point as a separate entity, we think of it as an instance of a particular concept, and ignore its idiosyncrasies. When we think of ‘sand’, we are rarely concerned about the characteristics of each individual grain. Similarly, in the ‘unfair coin flips’ example, we group sequences by their number of heads and tails, ignoring their order. In the case of the high-dimensional Gaussian, the natural grouping of points is based on their Euclidean distance from the mode. A more high-level example is that of natural images, where individual pixel values across localised regions of the image combine to form edges, textures, or even objects. There are usually many combinations of pixel values that give rise to the same texture, and we aren’t able to visually distinguish these particular instances unless we carefully study them side by side.
The following is perhaps a bit of an unfounded generalisation based on my own experience, but our brains seem hardwired to perform this kind of abstraction, so that we can reason about things in the familiar low-dimensional setting. It seems to happen unconsciously and continuously, and bypassing it requires a proactive approach.
Typicality

Informally, typicality refers to the characteristics that samples from a distribution tend to exhibit on average (in expectation). In the ‘unfair coin flip’ example, a sequence with 12 heads and 4 tails is ‘typical’. A sequence with 6 heads and 10 tails is highly atypical. Typical sequences contain an average amount of information: they are not particularly surprising or (un)informative.
We can formalise this intuition using the entropy of the distribution: a typical set \(\mathcal{T}_\varepsilon \subset \mathcal{X}\) is a set of sequences from \(\mathcal{X}\) whose probability is close to \(2^{-H}\), where \(H\) is the entropy of the distribution that the sequences were drawn from, measured in bits:
\[\mathcal{T}_\varepsilon = \{ \mathbf{x} \in \mathcal{X}: 2^{-(H + \varepsilon)} \leq p(\mathbf{x}) \leq 2^{-(H - \varepsilon)} \} .\]This means that the negative log likelihood of each such sequence is close to the entropy. Note that a distribution doesn’t have just one typical set: we can define many typical sets based on how close the probability of the sequences contained therein should be to \(2^{-H}\), by choosing different values of \(\varepsilon > 0\).
This concept was originally defined in an information-theoretic context, but I want to focus on machine learning, where I feel it is somewhat undervalued. It is often framed in terms of sequences sampled from stationary ergodic processes, but it is useful more generally for distributions of any kind of high-dimensional data points, both continuous and discrete, regardless of whether we tend to think of them as sequences.
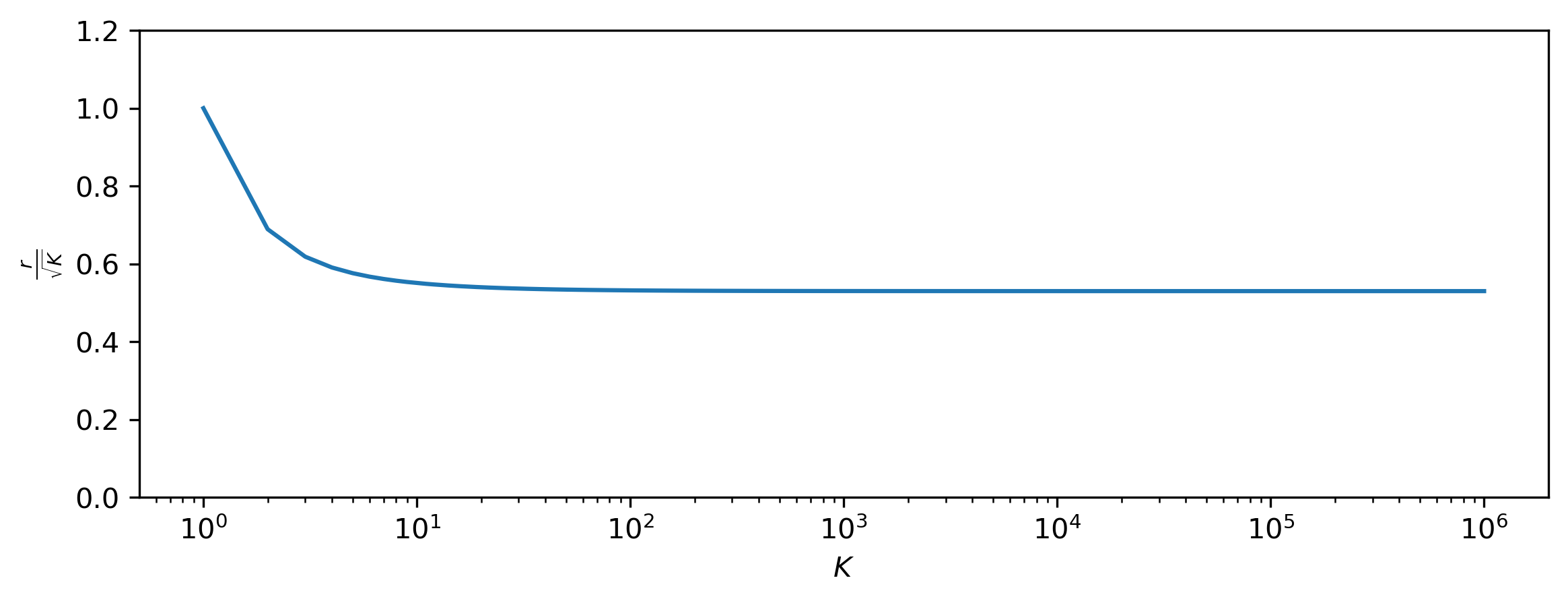
Why is this relevant to our discussion of abstraction and flawed human intuitions? As the dimensionality increases, the probability that any random sample from a distribution is part of a given typical set \(\mathcal{T}_\varepsilon\) tends towards 1. In other words, randomly drawn samples will almost always be ‘typical’, and the typical set covers most of the support of the distribution (this is a consequence of the so-called asymptotic equipartition property (AEP)). This happens even when \(\varepsilon\) is relatively small, as long as the dimensionality is high enough. This is visualised for a 100-dimensional standard Gaussian distribution below (based on empirical measurements, to avoid having to calculate some gnarly 100D integrals).
import matplotlib.pyplot as plt
import numpy as np
N = 1000000
K = 100
samples = np.random.normal(0, 1, (N, K))
radii = np.sqrt(np.sum(samples**2, axis=-1))
epsilon = np.logspace(-1, 2, 200)
lo = np.sqrt(np.maximum(K - epsilon * np.log(4), 0))
hi = np.sqrt(K + epsilon * np.log(4))
radius_range = hi - lo
mass = [np.mean((lo[i] < radii) & (radii < hi[i])) for i in range(len(epsilon))]
plt.figure(figsize=(9, 3))
plt.plot(radius_range, mass)
plt.xlabel('Difference between the min. and max. radii inside '
'$\\mathcal{T}_\\varepsilon$ for given $\\varepsilon$')
plt.ylabel('Total probability mass in $\\mathcal{T}_\\varepsilon$')
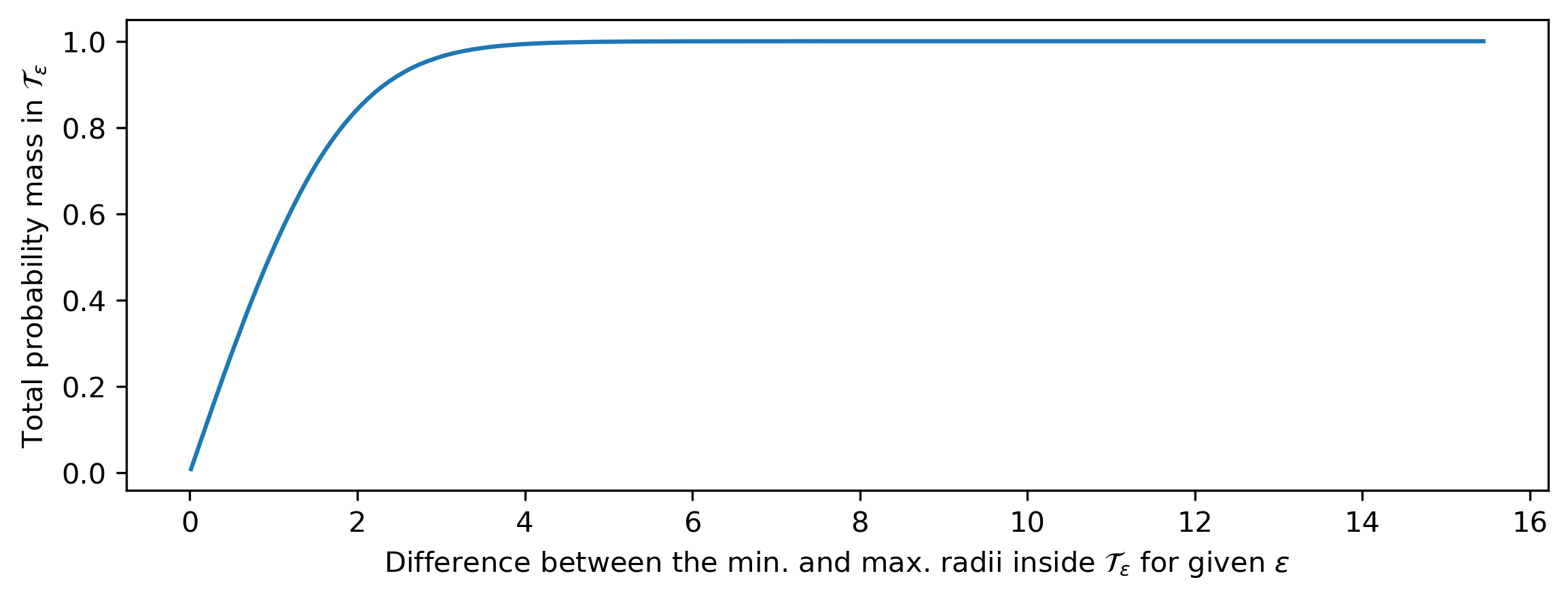
But this is where it gets interesting: for unimodal high-dimensional distributions, such as the multivariate Gaussian, the mode (i.e. the most likely value) usually isn’t part of the typical set. More generally, individual samples from high-dimensional (and potentially multimodal) distributions that have an unusually high likelihood are not typical, so we wouldn’t expect to see them when sampling. This can seem paradoxical, because they are by definition very ‘likely’ samples — it’s just that there are so few of them! Think about how surprising it would be to randomly sample the zero vector (or something very close to it) from a 100-dimensional standard Gaussian distribution.
This has some important implications: if we want to learn more about what a high-dimensional distribution looks like, studying the most likely samples is usually a bad idea. If we want to obtain a good quality sample from a distribution, subject to constraints, we should not be trying to find the single most likely one. Yet in machine learning, these are things that we do on a regular basis. In the next section, I’ll discuss a few situations where this paradox comes up in practice. For a more mathematical treatment of typicality and the curse of dimensionality, check out this case study by Bob Carpenter.
Typicality in the wild

A significant body of literature, spanning several subfields of machine learning, has sought to interpret and/or mitigate the unintuitive ways in which high-dimensional probability distributions behave. In this section, I want to highlight a few interesting papers and discuss them in relation to the concept of typicality. Note that I’ve made a selection based on what I’ve read recently, and this is not intended to be a comprehensive overview of the literature. In fact, I would appreciate pointers to other related work (papers and blog posts) that I should take a look at!
Language modelling
In conditional language modelling tasks, such as machine translation or image captioning, it is common to use conditional autoregressive models in combination with heuristic decoding strategies such as beam search. The underlying idea is that we want to find the most likely sentence (i.e. the mode of the conditional distribution, ‘MAP decoding’), but since this is intractable, we’ll settle for an approximate result instead.
With typicality in mind, it’s clear that this isn’t necessarily the best idea. Indeed, researchers have found that machine translation results, measured using the BLEU metric, sometimes get worse when the beam width is increased2 3. A higher beam width gives a better, more computationally costly approximation to the mode, but not necessarily better translation results. In this case, it’s tempting to blame the metric itself, which obviously isn’t perfect, but this effect has also been observed with human ratings4, so that cannot be the whole story.
A recent paper by Eikema & Aziz5 provides an excellent review of recent work in this space, and makes a compelling argument for MAP decoding as the culprit behind many of the pathologies that neural machine translation systems exhibit (rather than their network architectures or training methodologies). They also propose an alternative decoding strategy called ‘minimum Bayes risk’ (MBR) decoding that takes into account the whole distribution, rather than only the mode.
In unconditional language modelling, beam search hasn’t caught on, but not for want of trying! Stochasticity of the result is often desirable in this setting, and the focus has been on sampling strategies instead. In The Curious Case of Neural Text Degeneration6, Holtzman et al. observe that maximising the probability leads to poor quality results that are often repetitive. Repetitive samples may not be typical, but they have high likelihoods simply because they are more predictable.
They compare a few different sampling strategies that interpolate between fully random sampling and greedy decoding (i.e. predicting the most likely token at every step in the sequence), including the nucleus sampling technique which they propose. The motivation for trying to find a middle ground is that models will assign low probabilities to sequences that they haven’t seen much during training, which makes low-probability predictions inherently less reliable. Therefore, we want to avoid sampling low-probability tokens to some extent.
Zhang et al.4 frame the choice of a language model decoding strategy as a trade-off between diversity and quality. However, they find that reducing diversity only helps quality up to a point, and reducing it too much makes the results worse, as judged by human evaluators. They call this ‘the likelihood trap’: human-judged quality of samples correlates very well with likelihood, up to an inflection point, where the correlation becomes negative.
In the context of typicality, this raises an interesting question: where exactly is this inflection point, and how does it relate to the typical set of the model distribution? I think it would be very interesting to determine whether the inflection point coincides exactly with the typical set, or whether it is more/less likely. Perhaps there is some degree of atypicality that human raters will tolerate? If so, can we quantify it? This wouldn’t be far-fetched: think about our preference for celebrity faces over ‘typical’ human faces, for example!
Image modelling
The previously mentioned ‘note on the evaluation of generative models’1 is a seminal piece of work that demonstrates several ways in which likelihoods in the image domain can be vastly misleading.
In ‘Do Deep Generative Models Know What They Don’t Know?’7, Nalisnick et al. study the behaviour of likelihood-based models when presented with out-of-domain data. They observe how models can assign higher likelihoods to datasets other than their training datasets. Crucially, they show this for different classes of likelihood-based models (variational autoencoders, autoregressive models and flow-based models, see Figure 3 in the paper), which clearly demonstrates that this is an issue with the likelihood-based paradigm itself, and not with a particular model architecture or formulation.
Comparing images from CIFAR-10 and SVHN, two of the datasets they use, a key difference is the prevalence of textures in CIFAR-10 images, and the relative absence of such textures in SVHN images. This makes SVHN images inherently easier to predict, which partially explains why models trained on CIFAR-10 tend to assign higher likelihoods to SVHN images. Despite this, we clearly wouldn’t ever be able to sample anything that looks like an SVHN image from a CIFAR-10-trained model, because such images are not in the typical set of the model distribution (even if their likelihood is higher).
Audio modelling
I don’t believe I’ve seen any recent work that studies sampling and decoding strategies for likelihood-based models in the audio domain. Nevertheless, I wanted to briefly discuss this setting because a question I often get is: “why don’t you use greedy decoding or beam search to improve the quality of WaveNet samples?”
If you’ve read this far, the answer is probably clear to you by now: because audio samples outside of the typical set sound really weird! In fact, greedy decoding from a WaveNet will invariably yield complete silence, even for fairly strongly conditioned models (e.g. WaveNets for text-to-speech synthesis). In the text-to-speech case, even if you simply reduce the sampling temperature a bit too aggressively, certain consonants that are inherently noisy (such as ‘s’, ‘f’, ‘sh’ and ‘h’, the fricatives) will start sounding very muffled. These sounds are effectively different kinds of noise, and reducing the stochasticity of this noise has an audible effect.
Anomaly detection
Anomaly detection, or out-of-distribution (OOD) detection, is the task of identifying whether a particular input could have been drawn from a given distribution. Generative models are often used for this purpose: train an explicit model on in-distribution data, and then use its likelihood estimates to identify OOD inputs.
Usually, the assumption is made that OOD inputs will have low likelihoods, and in-distribution inputs will have high likelihoods. However, the fact that the mode of a high-dimensional distribution usually isn’t part of its typical set clearly contradicts this. This mistaken assumption is quite pervasive. Only recently has it started to be challenged explicitly, e.g. in works by Nalisnick et al.8 and Morningstar et al.9. Both of these works propose testing the typicality of inputs, rather than simply measuring and thresholding their likelihood.
The right level of abstraction

While our intuitive notion of likelihood in high-dimensional spaces might technically be wrong, it can often be a better representation of what we actually care about. This raises the question: should we really be fitting our generative models using likelihood measured in the input space? If we were to train likelihood-based models with ‘intuitive’ likelihood, they might perform better according to perceptual metrics, because they do not have to waste capacity capturing all the idiosyncrasies of particular examples that we don’t care to distinguish anyway.
In fact, measuring likelihood in more abstract representation spaces has had some success in generative modelling, and I think the approach should be taken more seriously in general. In language modelling, it is common to measure likelihoods at the level of word pieces, rather than individual characters. In symbolic music modelling, recent models that operate on event-based sequences (rather than sequences with a fixed time quantum) are more effective at capturing large-scale structure10. Some likelihood-based generative models of images separate or discard the least-significant bits of each pixel colour value, because they are less perceptually relevant, allowing model capacity to be used more efficiently11 12.
But perhaps the most striking example is the recent line of work where VQ-VAE13 is used to learn discrete higher-level representations of perceptual signals, and generative models are then trained to maximise the likelihood in this representation space. This approach has led to models that produce images that are on par with those produced by GANs in terms of fidelity, and exceed them in terms of diversity14 15 16. It has also led to models that are able to capture long-range temporal structure in audio signals, which even GANs had not been able to do before17 18. While the current trend in representation learning is to focus on coarse-grained representations which are suitable for discriminative downstream tasks, I think it also has a very important role to play in generative modelling.
In the context of modelling sets with likelihood-based models, a recent blog post by Adam Kosiorek drew my attention to point processes, and in particular, to the formula that expresses the density over ordered sequences in terms of the density over unordered sets. This formula quantifies how we need to scale probabilities across sets of different sizes to make them comparable. I think it may yet prove useful to quantify the unintuitive behaviours of likelihood-based models.
Closing thoughts

To wrap up this post, here are some takeaways:
-
High-dimensional spaces, and high-dimensional probability distributions in particular, are deeply unintuitive in more ways than one. This is a well-known fact, but they still manage to surprise us sometimes!
-
The most likely samples from a high-dimensional distribution usually aren’t a very good representation of that distribution. In most situations, we probably shouldn’t be trying to find them.
-
Typicality is a very useful concept to describe these unintuitive phenomena, and I think it is undervalued in machine learning — at least in the work that I’ve been exposed to.
-
A lot of work that discusses these issues (including some that I’ve highlighted in this post) doesn’t actually refer to typicality by name. I think doing so would improve our collective understanding, and shed light on links between related phenomena in different subfields.
If you have any thoughts about this topic, please don’t hesitate to share them in the comments below!
In an addendum to this post, I explore quantitatively what happens when our intuitions fail us in high-dimensional spaces.
If you would like to cite this post in an academic context, you can use this BibTeX snippet:
@misc{dieleman2020typicality,
author = {Dieleman, Sander},
title = {Musings on typicality},
url = {https://benanne.github.io/2020/09/01/typicality.html},
year = {2020}
}
Acknowledgements
Thanks to Katie Millican, Jeffrey De Fauw and Adam Kosiorek for their valuable input and feedback on this post!
References
-
Theis, van den Oord and Bethge, “A note on the evaluation of generative models”, International Conference on Learning Representations, 2016. ↩ ↩2
-
Koehn & Knowles, “Six Challenges for Neural Machine Translation”, First Workshop on Neural Machine Translation, 2017. ↩
-
Ott, Auli, Grangier and Ranzato, “Analyzing Uncertainty in Neural Machine Translation”, International Conference on Machine Learning, 2018. ↩
-
Zhang, Duckworth, Ippolito and Neelakantan, “Trading Off Diversity and Quality in Natural Language Generation”, arXiv, 2020. ↩ ↩2
-
Eikema and Aziz, “Is MAP Decoding All You Need? The Inadequacy of the Mode in Neural Machine Translation”, arXiv, 2020. ↩
-
Holtzman, Buys, Du, Forbes and Choi, “The Curious Case of Neural Text Degeneration”, International Conference on Learning Representations, 2020. ↩
-
Nalisnick, Matsukawa, Teh, Gorur and Lakshminarayanan, “Do Deep Generative Models Know What They Don’t Know?”, International Conference on Learnign Representations, 2019. ↩
-
Nalisnick, Matuskawa, Teh and Lakshminarayanan, “Detecting Out-of-Distribution Inputs to Deep Generative Models Using Typicality”, arXiv, 2019. ↩
-
Morningstar, Ham, Gallagher, Lakshminarayanan, Alemi and Dillon, “Density of States Estimation for Out-of-Distribution Detection”, arXiv, 2020. ↩
-
Oore, Simon, Dieleman, Eck and Simonyan, “This Time with Feeling: Learning Expressive Musical Performance”, Neural Computing and Applications, 2020. ↩
-
Menick and Kalchbrenner, “Generating High Fidelity Images with Subscale Pixel Networks and Multidimensional Upscaling”, International Conference on Machine Learning, 2019. ↩
-
Kingma & Dhariwal, “Glow: Generative flow with invertible 1x1 convolutions”, Neural Information Processing Systems, 2018. ↩
-
van den Oord, Vinyals and Kavukcuoglu, “Neural Discrete Representation Learning”, Neural Information Processing Systems, 2017. ↩
-
Razavi, van den Oord and Vinyals, “Generating Diverse High-Fidelity Images with VQ-VAE-2”, Neural Information Processing Systems, 2019. ↩
-
De Fauw, Dieleman and Simonyan, “Hierarchical Autoregressive Image Models with Auxiliary Decoders”, arXiv, 2019. ↩
-
Ravuri and Vinyals, “Classification Accuracy Score for Conditional Generative Models”, Neural Information Processing Systems, 2019. ↩
-
Dieleman, van den Oord and Simonyan, “The challenge of realistic music generation: modelling raw audio at scale”, Neural Information Processing Systems, 2018. ↩
-
Dhariwal, Jun, Payne, Kim, Radford and Sutskever, “Jukebox: A Generative Model for Music”, arXiv, 2020. ↩