My main research interests are in generative modelling and representation learning of media, including audio/music, images and video, and diffusion models in particular. I have also worked on music recommendation and image classification in the past. Selected papers and projects are listed below, please refer to Google Scholar for a complete list of my publications.
Generative models of media at Google DeepMind
I have contributed to several generative models of media at Google DeepMind, including:
- Lyria, a music generation model
- Imagen 2 and Imagen 3, image generation models
- Veo, a video generation model
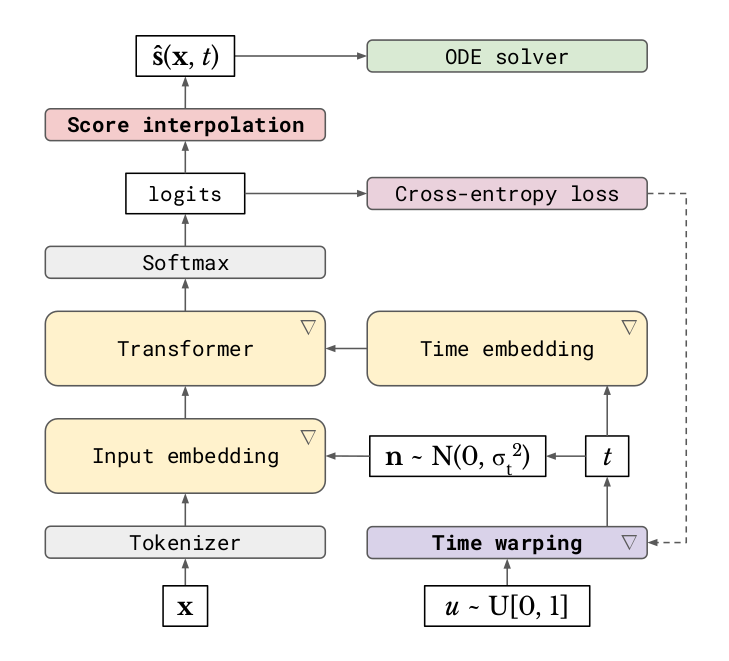
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, Curtis Hawthorne, Rémi Leblond, Will Grathwohl, Jonas Adler
Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
Variable-rate discrete representation learning
Sander Dieleman, Charlie Nash, Jesse Engel, Karen Simonyan
Semantically meaningful information content in perceptual signals is usually unevenly distributed. In speech signals for example, there are often many silences, and the speed of pronunciation can vary considerably. In this work, we propose slow autoencoders (SlowAEs) for unsupervised learning of high-level variable-rate discrete representations of sequences, and apply them to speech. We show that the resulting event-based representations automatically grow or shrink depending on the density of salient information in the input signals, while still allowing for faithful signal reconstruction. We develop run-length Transformers (RLTs) for event-based representation modelling and use them to construct language models in the speech domain, which are able to generate grammatical and semantically coherent utterances and continuations.
High Fidelity Speech Synthesis with Adversarial Networks
Mikołaj Bińkowski, Jeff Donahue, Sander Dieleman, Aidan Clark, Erich Elsen, Norman Casagrande, Luis C. Cobo, Karen Simonyan
Generative adversarial networks have seen rapid development in recent years and have led to remarkable improvements in generative modelling of images. However, their application in the audio domain has received limited attention, and autoregressive models, such as WaveNet, remain the state of the art in generative modelling of audio signals such as human speech. To address this paucity, we introduce GAN-TTS, a Generative Adversarial Network for Text-to-Speech. Our architecture is composed of a conditional feed-forward generator producing raw speech audio, and an ensemble of discriminators which operate on random windows of different sizes. The discriminators analyse the audio both in terms of general realism, as well as how well the audio corresponds to the utterance that should be pronounced. To measure the performance of GAN-TTS, we employ both subjective human evaluation (MOS - Mean Opinion Score), as well as novel quantitative metrics (Fréchet DeepSpeech Distance and Kernel DeepSpeech Distance), which we find to be well correlated with MOS. We show that GAN-TTS is capable of generating high-fidelity speech with naturalness comparable to the state-of-the-art models, and unlike autoregressive models, it is highly parallelisable thanks to an efficient feed-forward generator.
Paper (arXiv) - Audio sample (WAV)
Piano Genie
Chris Donahue, Ian Simon, Sander Dieleman
We present Piano Genie, an intelligent controller which allows non-musicians to improvise on the piano. With Piano Genie, a user performs on a simple interface with eight buttons, and their performance is decoded into the space of plausible piano music in real time. To learn a suitable mapping procedure for this problem, we train recurrent neural network autoencoders with discrete bottlenecks: an encoder learns an appropriate sequence of buttons corresponding to a piano piece, and a decoder learns to map this sequence back to the original piece. During performance, we substitute a user’s input for the encoder output, and play the decoder’s prediction each time the user presses a button. To improve the intuitiveness of Piano Genie’s performance behavior, we impose musically meaningful constraints over the encoder’s outputs.
Paper (arXiv) - Blog post - Live demo

Hierarchical Autoregressive Image Models with Auxiliary Decoders
Jeffrey De Fauw, Sander Dieleman, Karen Simonyan
Autoregressive generative models of images tend to be biased towards capturing local structure, and as a result they often produce samples which are lacking in terms of large-scale coherence. To address this, we propose two methods to learn discrete representations of images which abstract away local detail. We show that autoregressive models conditioned on these representations can produce high-fidelity reconstructions of images, and that we can train autoregressive priors on these representations that produce samples with large-scale coherence. We can recursively apply the learning procedure, yielding a hierarchy of progressively more abstract image representations. We train hierarchical class-conditional autoregressive models on the ImageNet dataset and demonstrate that they are able to generate realistic images at resolutions of 128×128 and 256×256 pixels. We also perform a human evaluation study comparing our models with both adversarial and likelihood-based state-of-the-art generative models.
Paper (arXiv) - Samples (Google Drive)

Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, Douglas Eck
Generating musical audio directly with neural networks is notoriously difficult because it requires coherently modeling structure at many different timescales. Fortunately, most music is also highly structured and can be represented as discrete note events played on musical instruments. Herein, we show that by using notes as an intermediate representation, we can train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large advance in the state of the art is enabled by our release of the new MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset, composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. The networks and the dataset together present a promising approach toward creating new expressive and interpretable neural models of music.
Paper (arXiv) - Blog post - MAESTRO dataset
The challenge of realistic music generation: modelling raw audio at scale (NeurIPS 2018)
Sander Dieleman, Aäron van den Oord, Karen Simonyan
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
Paper - Audio samples (Google Drive)
WaveNet: a generative model for raw audio
Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-of-the-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
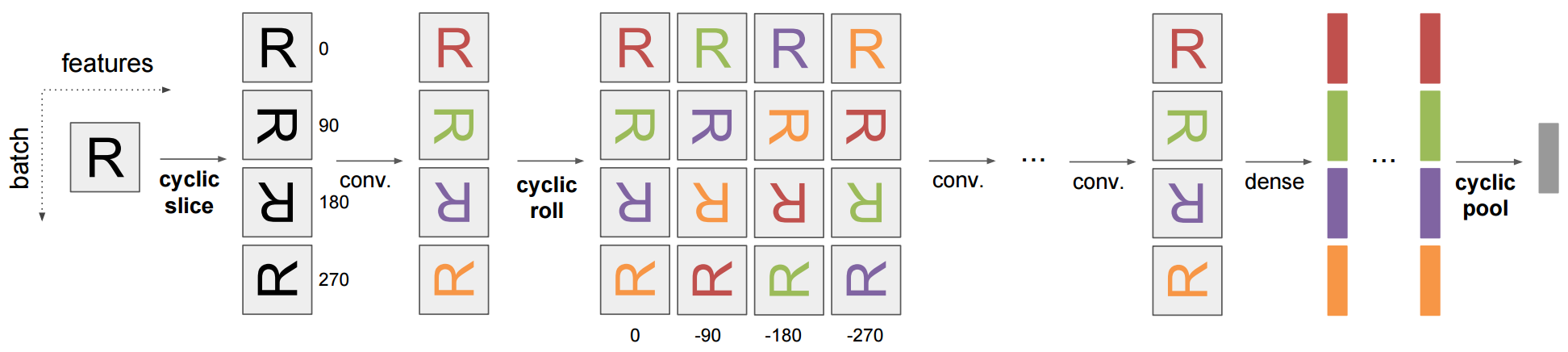
Exploiting cyclic symmetry in convolutional neural networks (ICML 2016)
Sander Dieleman, Jeffrey De Fauw, Koray Kavukcuoglu
Many classes of images exhibit rotational symmetry. Convolutional neural networks are sometimes trained using data augmentation to exploit this, but they are still required to learn the rotation equivariance properties from the data. Encoding these properties into the network architecture could result in a more efficient use of the parameter budget by relieving the model from learning them. We introduce four operations which can be inserted into neural network models as layers, and which can be combined to make these models partially equivariant to rotations.
Mastering the game of Go with deep neural networks and tree search (Nature)
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, Demis Hassabis
The game of Go has long been viewed as the most challenging of classic games for artificial intelligence owing to its enormous search space and the difficulty of evaluating board positions and moves. Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0. This is the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.
Learning feature hierarchies for musical audio signals (PhD Thesis)
Sander Dieleman
This is my PhD thesis, which I defended in January 2016. It covers most of my work on applying deep learning to content-based music information retrieval. My work on galaxy morphology prediction is included as an appendix. Part of the front matter is in Dutch, but the main matter is in English.
Rotation-invariant convolutional neural networks for galaxy morphology prediction (MNRAS)
Sander Dieleman, Kyle W. Willett, Joni Dambre
I wrote a paper about my winning entry for the Galaxy Challenge on Kaggle, which I also wrote about on this blog last year. In short, I trained convolutional neural networks for galaxy morphology prediction based on images, and made some modifications to the network architecture to exploit the rotational symmetry of the images. The paper was written together with one of the competition organizers and special attention is paid to how astronomers can actually benefit from this work.
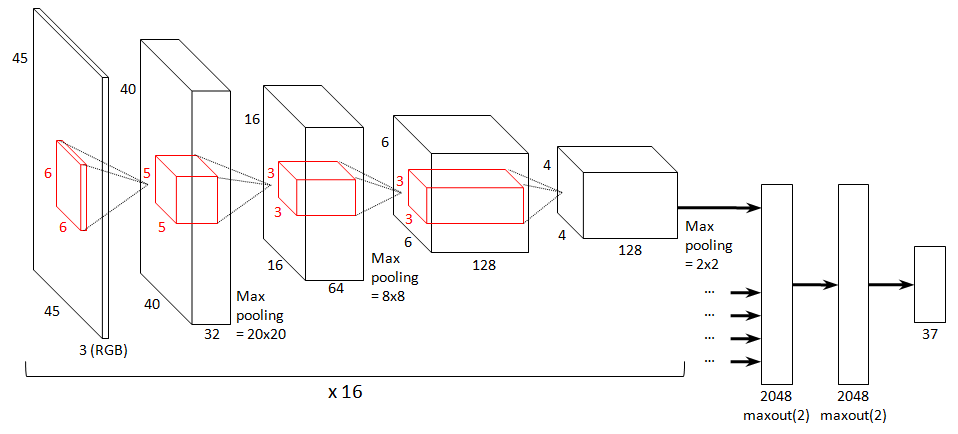
End-to-end learning for music audio (ICASSP 2014)
Sander Dieleman, Benjamin Schrauwen
Content-based music information retrieval tasks have traditionally been solved using engineered features and shallow processing architectures. In recent years, there has been increasing interest in using feature learning and deep architectures instead, thus reducing the required engineering effort and the need for prior knowledge. However, this new approach typically still relies on mid-level representations of music audio, e.g. spectrograms, instead of raw audio signals. In this paper, we investigate whether it is possible to train convolutional neural networks directly on raw audio signals. The networks are able to autonomously discover frequency decompositions from raw audio, as well as phase- and translation-invariant feature representations.
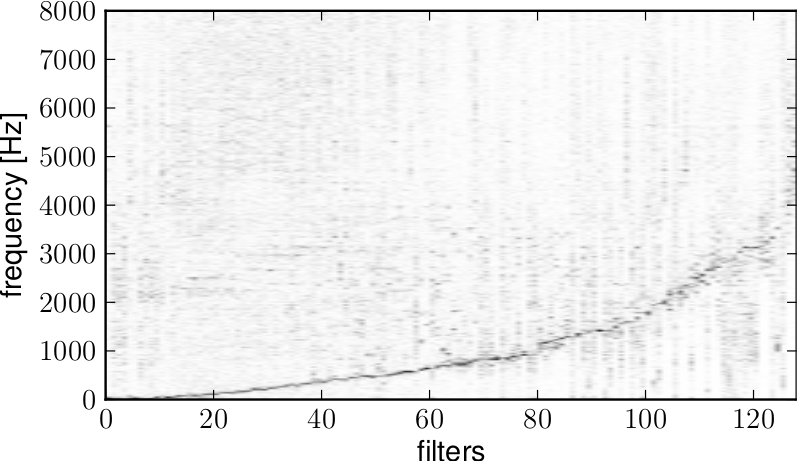
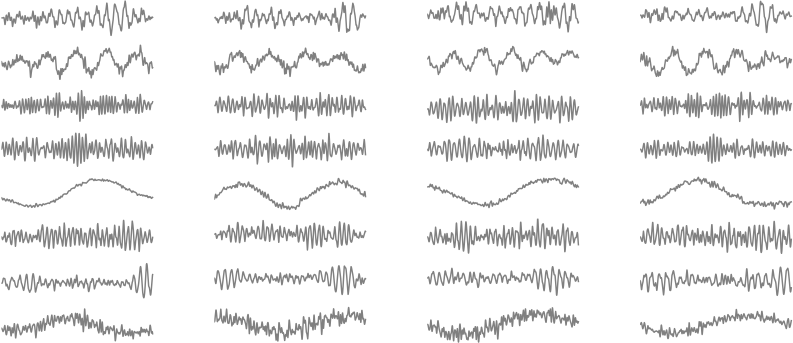
Deep content-based music recommendation (NIPS 2013)
Aäron van den Oord, Sander Dieleman, Benjamin Schrauwen
The collaborative filtering approach to music recommendation suffers from the cold start problem: it fails when no listening data is available, so it is not effective for recommending new and unpopular songs. In this paper, we use a latent factor model for recommendation, and predict the latent factors from music audio when they cannot be obtained from listening data, using a deep convolutional neural network. Predicted latent factors produce sensible recommendations, despite the fact that there is a large semantic gap between the characteristics of a song that affect user preference and the corresponding audio signal.
Paper (PDF) - BibTeX - Abstract

Multiscale approaches to music audio feature learning (ISMIR 2013)
Sander Dieleman, Benjamin Schrauwen
Recent results in feature learning indicate that simple algorithms such as K-means can be very effective, sometimes surpassing more complicated approaches based on restricted Boltzmann machines, autoencoders or sparse coding. Furthermore, there has been increased interest in multiscale representations of music audio recently. Such representations are more versatile because music audio exhibits structure on multiple timescales, which are relevant for different MIR tasks to varying degrees. We develop and compare three approaches to multiscale audio feature learning using the spherical K-means algorithm.