Ever since the rise of diffusion models, people have sought ways to make them faster and cheaper to sample from. About two years ago, I wrote a blog post about diffusion distillation, which is one of the main tools used to reduce the number of steps required to obtain high-quality samples. Although the core principles underlying various distillation methods have not changed, a lot of new variants have popped up since.
In this blog post, I want to take a closer look at flow maps. While diffusion models describe paths between noise and data by predicting the tangent direction at each point along the path, flow maps are instead able to predict any point on a path from any other point on that same path. They can be used for faster sampling, but they also have some other tricks up their sleeve, enabling more efficient reward-based learning and improved sampling steerability, among other things. They have recently become a very popular subject of study.
While it is relatively straightforward to define what a flow map is, there turn out to be many different ways to build and train them. On top of that, as with diffusion itself, the literature is once again rife with different formalisms and terminology, which makes for a confusing experience when trying to learn how everything fits together. I will do my best to clear things up a bit, based primarily on the taxonomy proposed by Boffi et al.1 2.
Flow maps build on the ideas behind diffusion models, and as usual, I will assume some familiarity with these ideas. Being comfortable with vector calculus will also help to understand how they are trained, but if that’s not you, hopefully the other parts of this blog post will still be interesting to you. You may want to consider (re-)reading some of my earlier blog posts for context (e.g. Perspectives on diffusion). Alternatively, Chieh-Hsin Lai and colleagues recently published a comprehensive monograph on diffusion models3, which combines math and rigour with intuitive explanations – highly recommended, both as a refresher and as a starting point.
Below is a table of contents. Click to jump directly to a particular section of this post.
- Charting paths from noise to data
- Three notions of consistency
- To backprop or not to backprop?
- Training flow maps from scratch
- Flow maps in practice
- Applications and extensions
- Alternative strategies
- Closing thoughts
- Acknowledgements
- References
Charting paths from noise to data

The key to understanding flow maps is the perspective of diffusion models as defining a bijection between noise and data, with unique paths connecting pairs of samples from each distribution, in such a way that they never cross each other. Therefore, let’s first take a closer look at diffusion sampling algorithms, and build towards flow maps from there.
Sampling from diffusion models
There are many different sampling algorithms available for diffusion models nowadays, but they all fall into one of two categories: stochastic or deterministic. The miracle of deterministic sampling is something I have written about before, but it is worth recapping here, as it is fundamental to the development of flow maps.
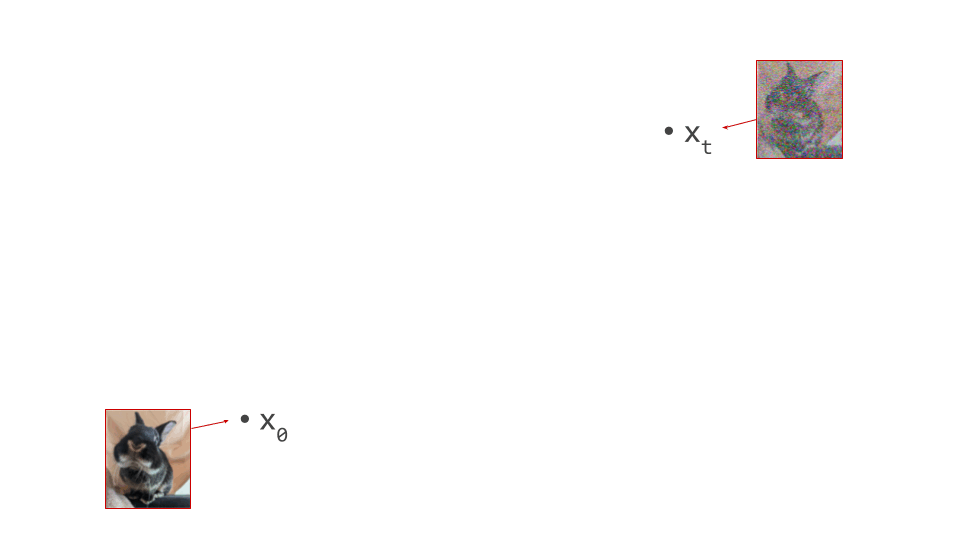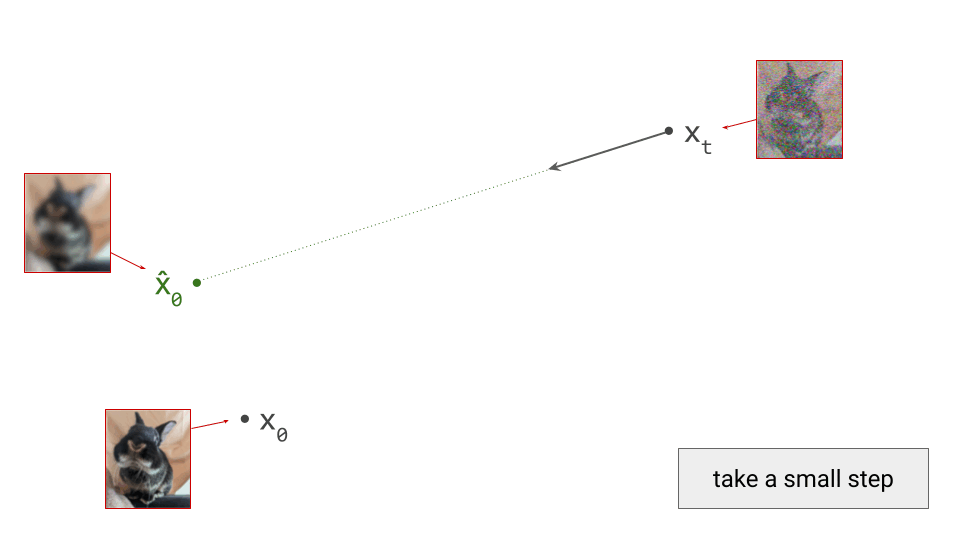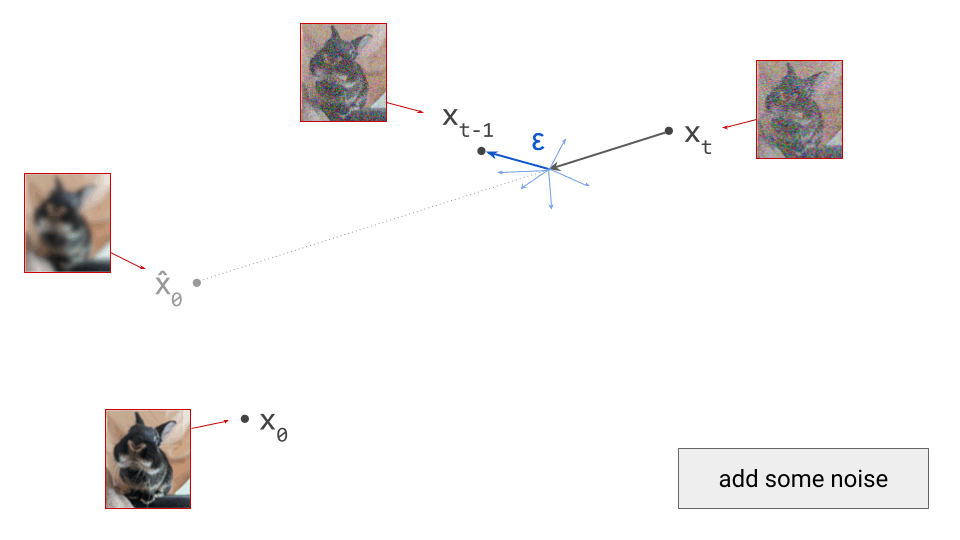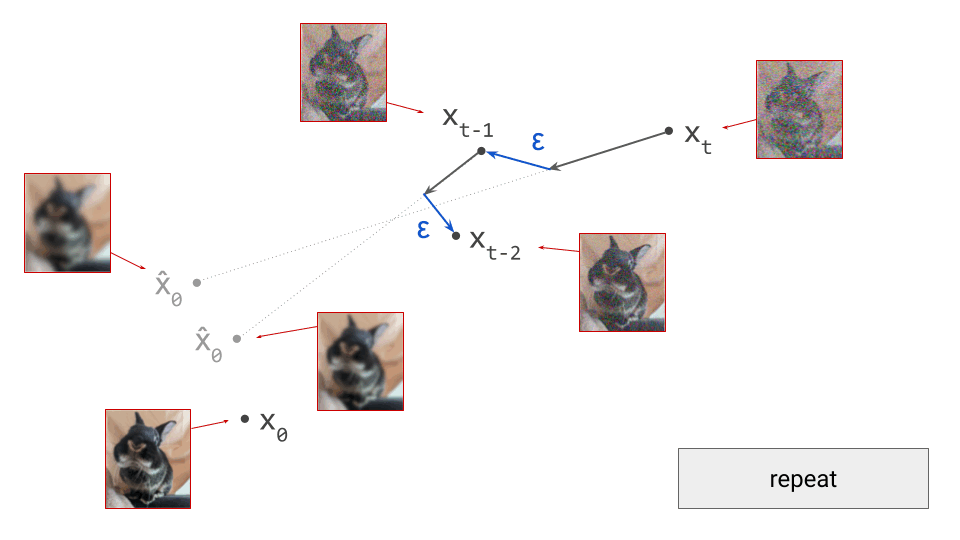
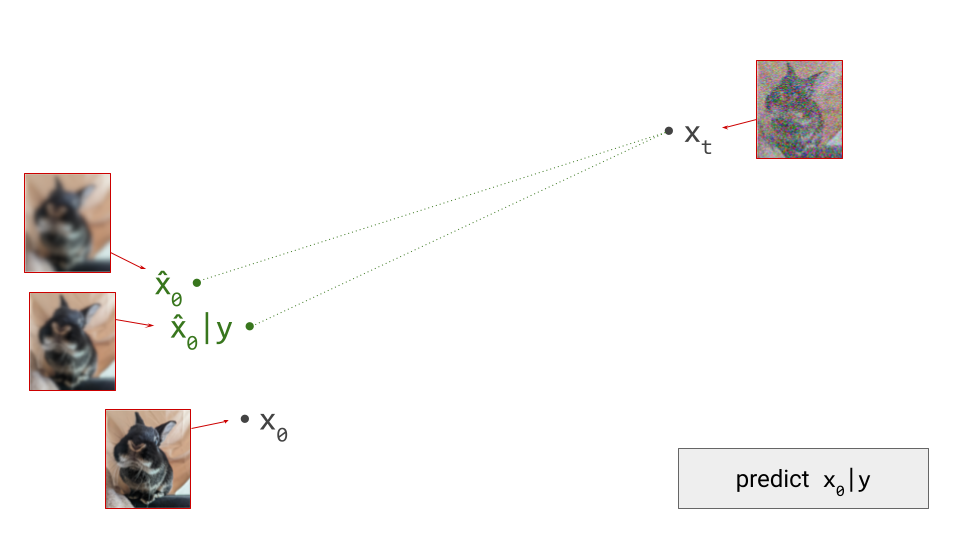
The gist of it is as follows: if we have a denoiser model that predicts the expected value of the clean original data \(\hat{\mathbf{x}}_0 = \mathbb{E}\left[ \mathbf{x}_0 \mid \mathbf{x}_t \right]\), given a noisy observation \(\mathbf{x}_t\), we can construct two distinct iterative generative procedures.
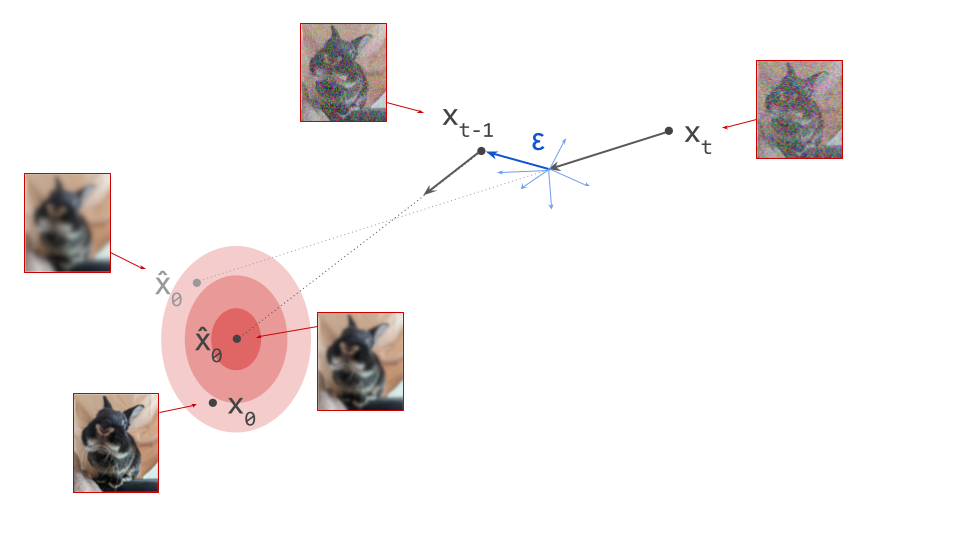
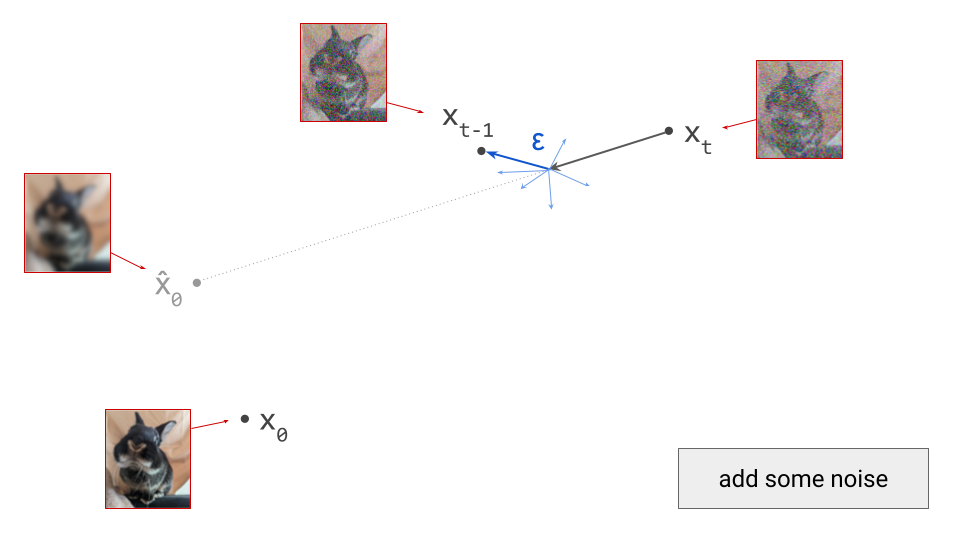
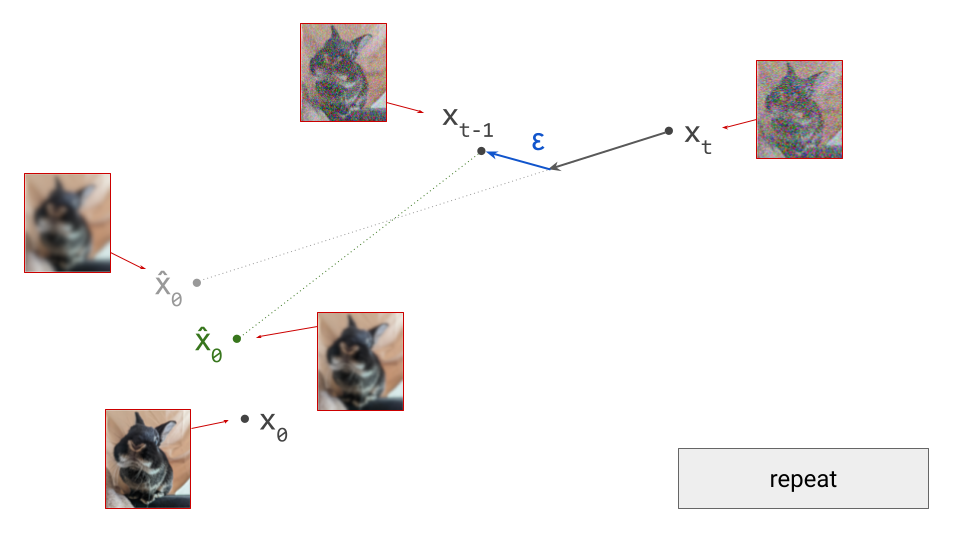
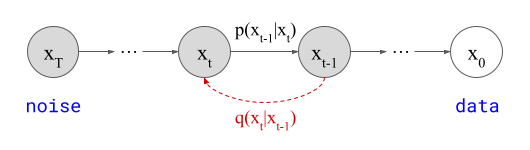
The stochastic one is the most intuitive: at each iteration, we sample from a conditional distribution of slightly less noisy examples, given the current noisy observation, \(p(\mathbf{x}_{t-1} \mid \mathbf{x}_t)\), to reverse the corruption process one step at a time. Conveniently, we can construct an approximation of this distribution using the denoiser model prediction \(\hat{\mathbf{x}}_0\). The smaller the interval between the noise levels at time steps \(t\) and \(t-1\), the more accurate the approximation will be. After many iterations, the noise fades, and we end up with a sample from the clean data distribution at \(t=0\). This is, in a nutshell, how the original DDPM4 algorithm works. Sampling algorithms based on the stochastic differential equation (SDE) formalism of diffusion models5 produce similar stochastic trajectories in input space.
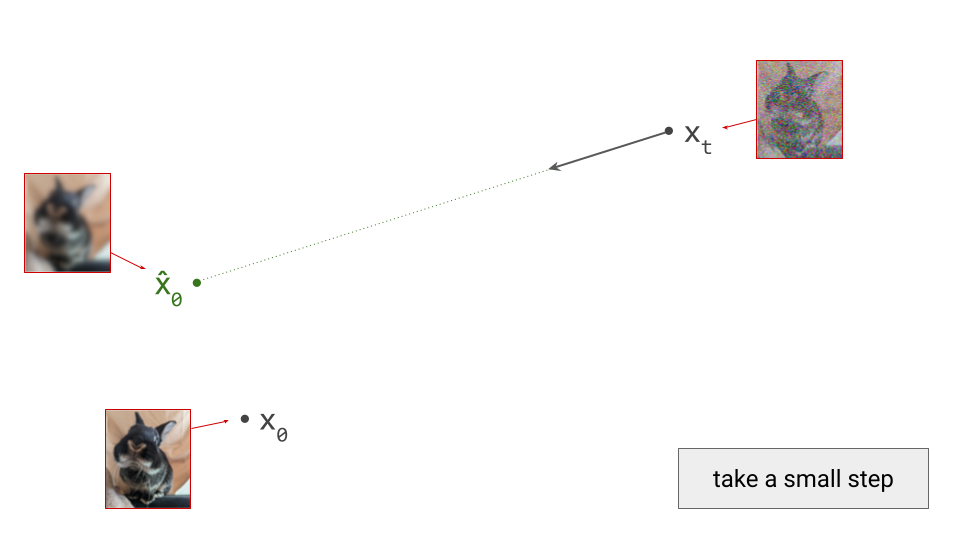
The deterministic procedure does not involve drawing random samples at any point, except at the very start: given the current noisy observation \(\mathbf{x}_t\) and the prediction \(\hat{\mathbf{x}}_0\) from the denoiser, there is a deterministic update rule that gives us \(\mathbf{x}_{t-1}\), which we can recursively apply until we get to \(\mathbf{x}_0\). Because every step of the procedure is deterministic, there is no randomness anywhere: from a given starting point \(\mathbf{x}_t\), we can only ever end up in one specific end point \(\mathbf{x}_0\). Such an update rule can be derived in the probabilistic framework (i.e. DDIM6), or using the ordinary differential equation (ODE) formalism5.
The default sampling algorithm used in Flow Matching7 is another instance of the deterministic procedure. Here, the neural network is typically parameterised to predict the velocity \(\mathbf{v}_t = \mathbb{E}\left[\mathbf{x}_T - \mathbf{x}_0 \mid \mathbf{x}_t \right]\) instead of the clean input \(\mathbb{E}\left[ \mathbf{x}_0 \mid \mathbf{x}_t \right]\) (with \(t=T\) the time step corresponding to the maximal noise level, i.e. pure Gaussian noise). However, as there is a linear relationship between \(\mathbf{v}_t\), \(\hat{\mathbf{x}}_0\) and \(\mathbf{x}_t\), this just yields a variant of the same underlying algorithm (see also this discussion of different diffusion model output parameterisations in an earlier blog post).
All these algorithms have in common that the marginal distributions of noisy examples \(p(\mathbf{x}_t)\) at each time step \(t\) are preserved: the distribution of \(\mathbf{x}_t\) does not depend on whether you chose to use a deterministic or stochastic sampling algorithm! This is of course not true at all for the conditional distributions \(p(\mathbf{x}_t \mid \mathbf{x}_T)\), which collapse to delta distributions in the deterministic case (all probability mass is on a single option). This preservation of the marginal distributions is also true for the special cases \(p(\mathbf{x}_0)\) and \(p(\mathbf{x}_T)\), at the data and noise sides respectively. If we look at specific individual examples rather than distributions, however, the path in input space traced out by the sampling process will look quite different.
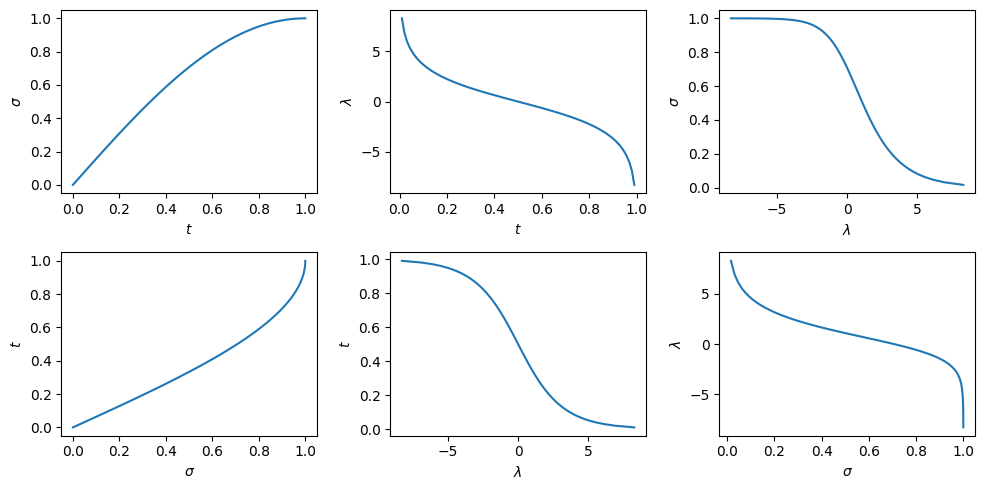
Below is a visualisation of the sampling process: stochastic on the left, deterministic on the right. I decided to show this for both a 1D example (top) and a 2D example (bottom), because I believe the insights they provide are complementary. In both cases, the target distribution is a mixture of two Gaussians. We start with samples from our noise distribution, which is a single Gaussian. As sampling progresses, the distribution gradually transforms into the target mixture. The path a single sample traverses is quite jagged and erratic in the stochastic case, but smooth and gently curved in the deterministic case. Two very different microscopic behaviours give rise to the exact same macroscopic behaviour!
Dead reckoning: tracking paths with a diffusion model
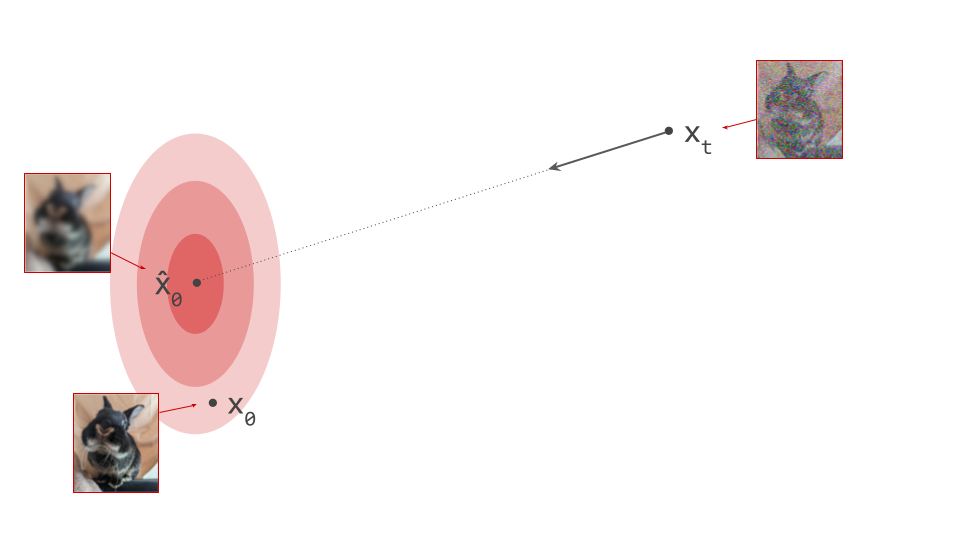
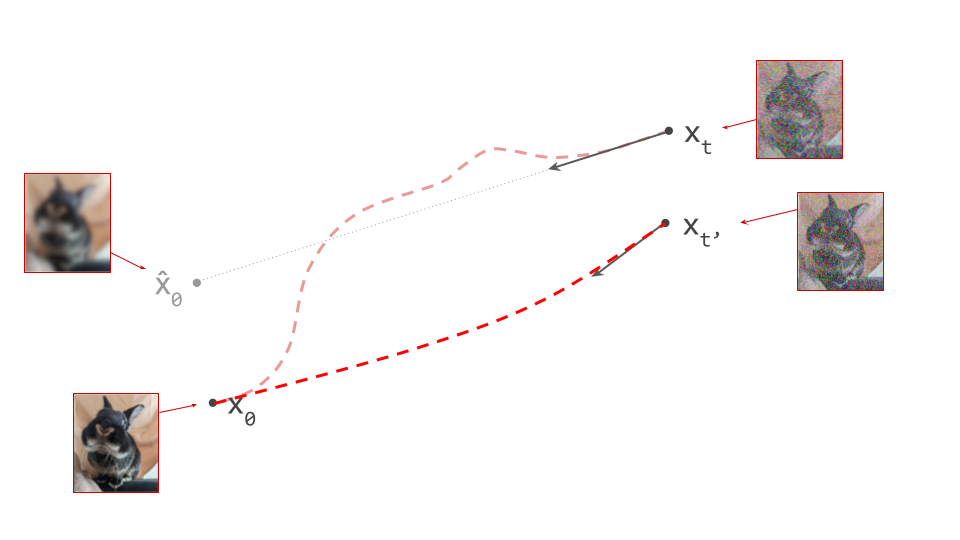
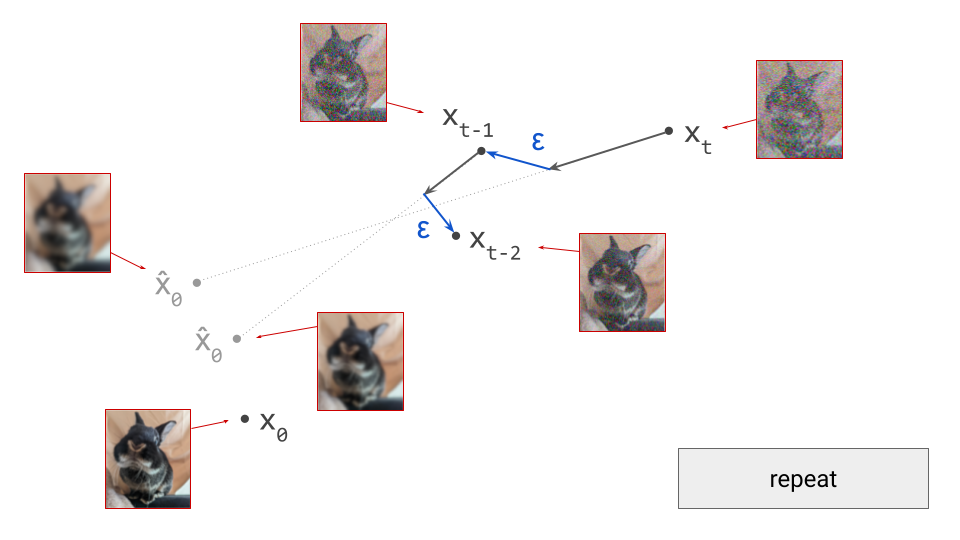
An important implication of the existence of deterministic sampling algorithms is that there must be a deterministic bijective mapping between individual samples from the noise and data distributions. Each noise sample is associated with a single specific data sample, and vice versa. Starting from a noise sample, we can follow a path through input space that leads us to the corresponding data sample. We do this simply by following the tangent direction to the path at each point, which is predicted by the denoiser. Note that we can also use the same tangent direction to guide us along the path in reverse, from data to noise.
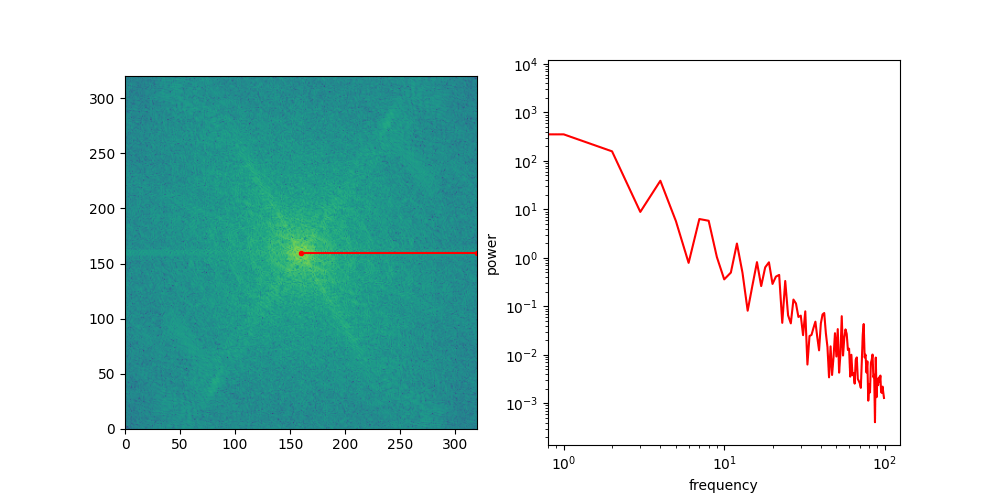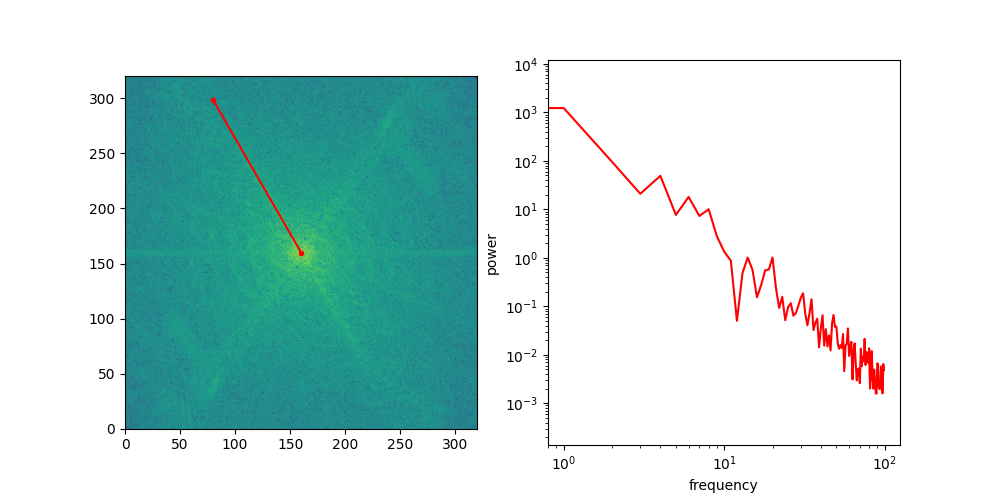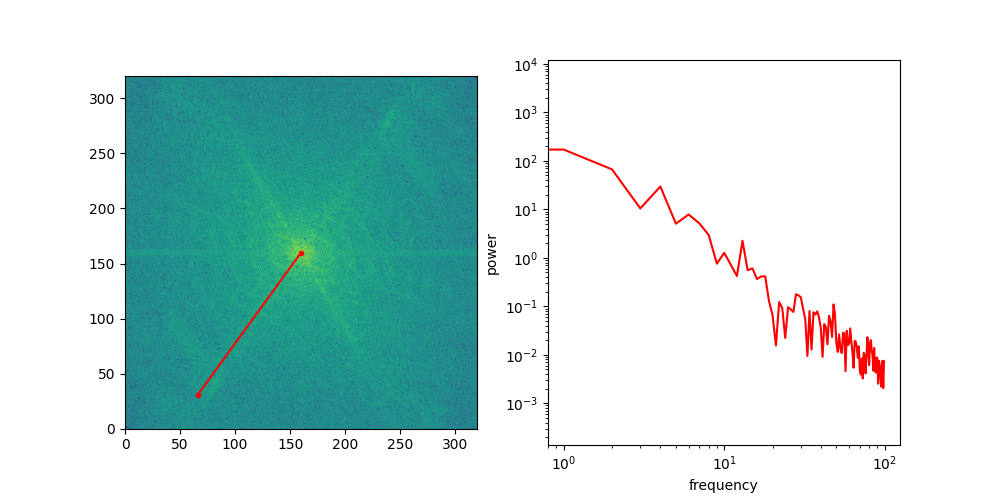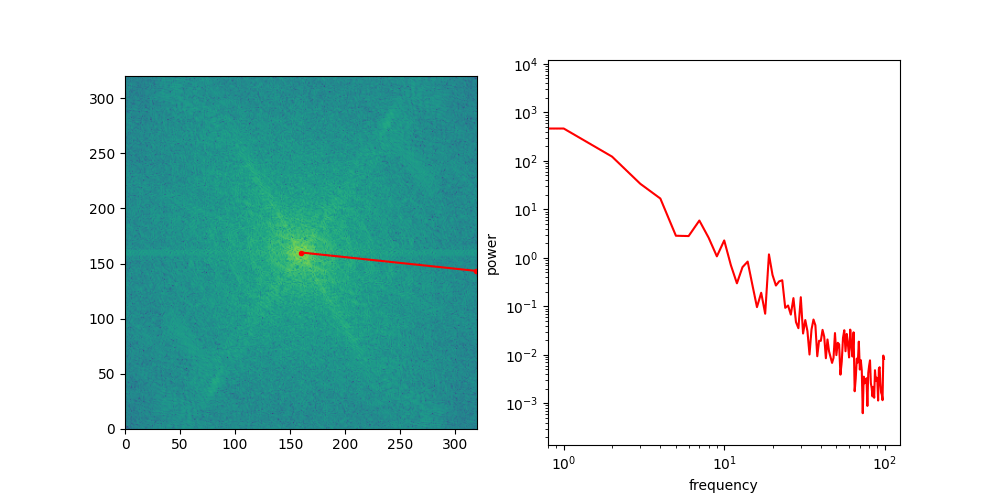
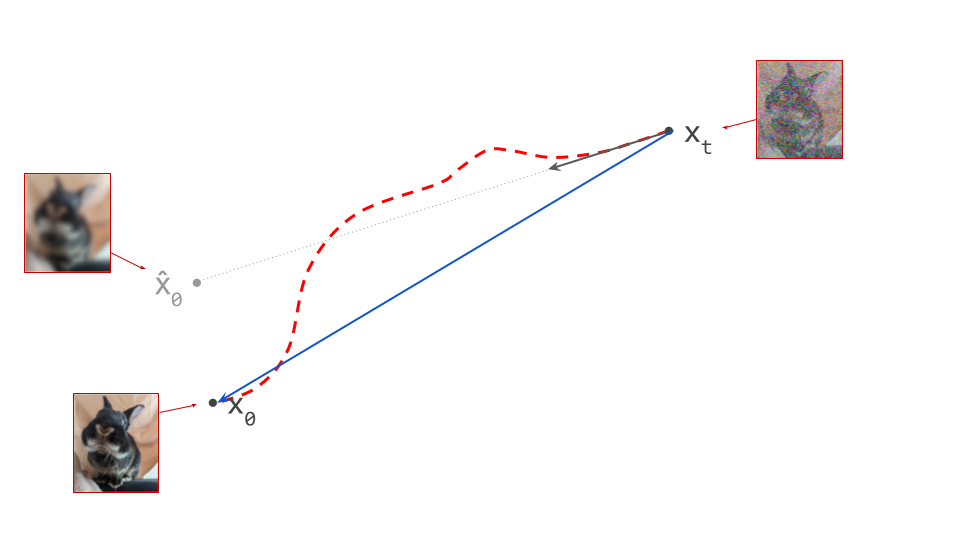
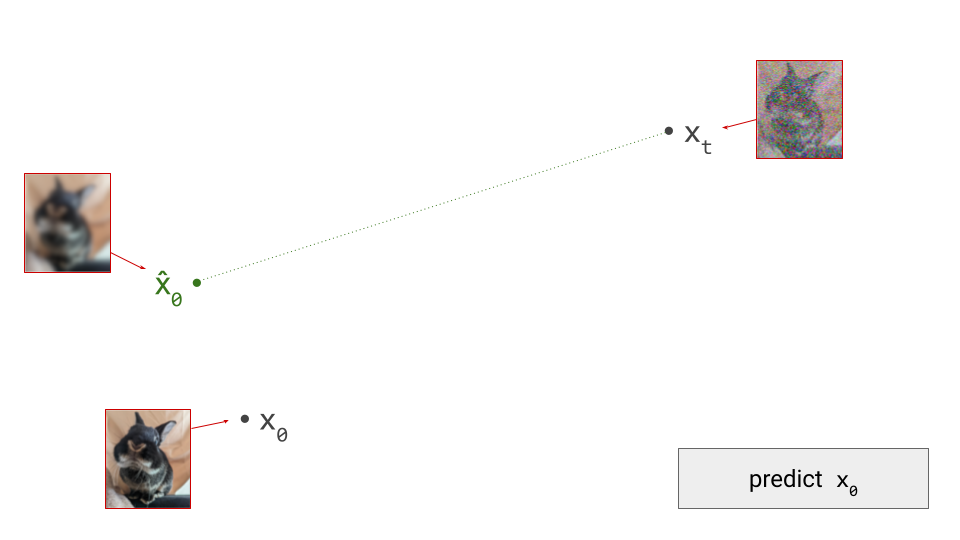
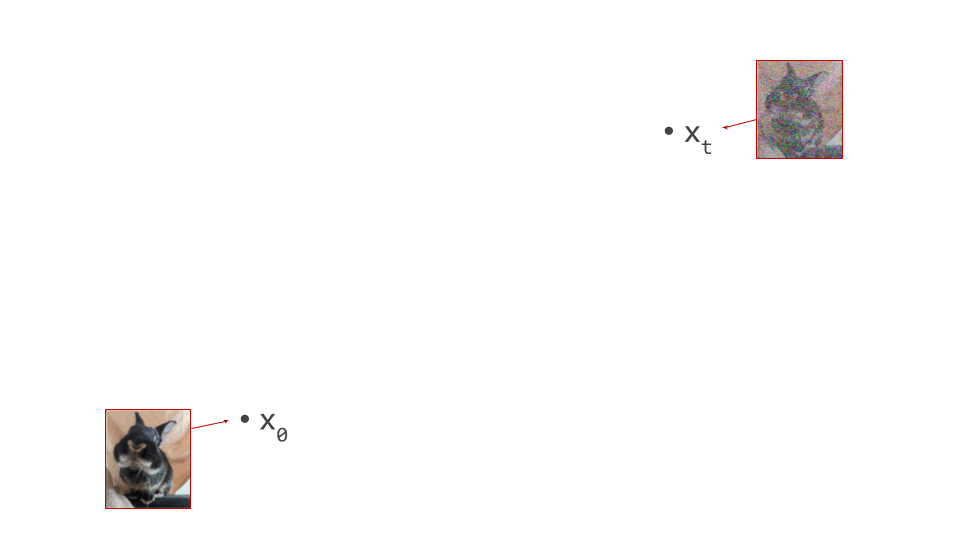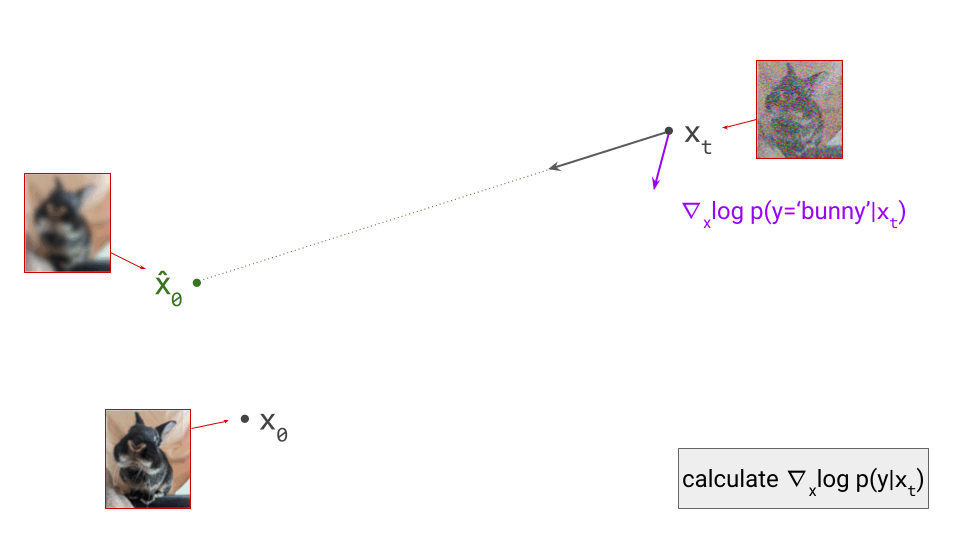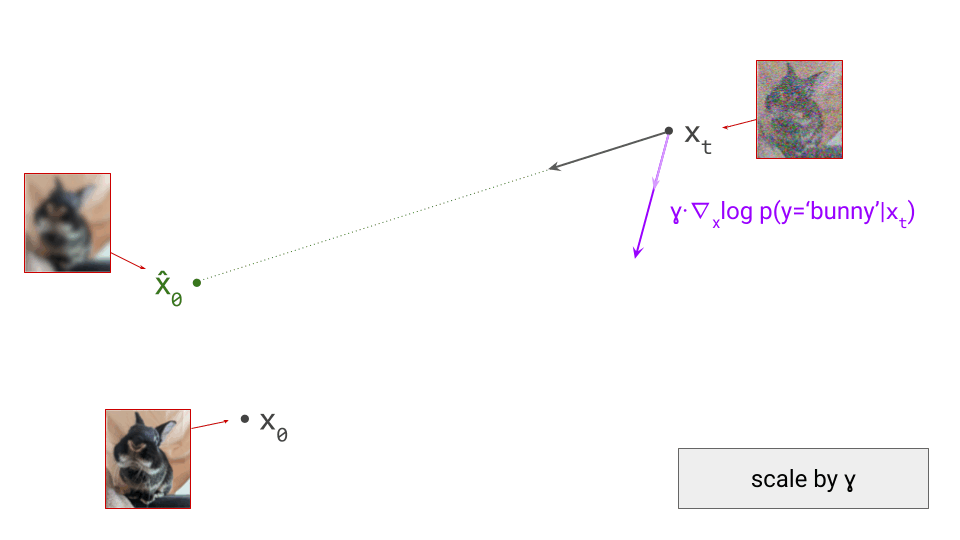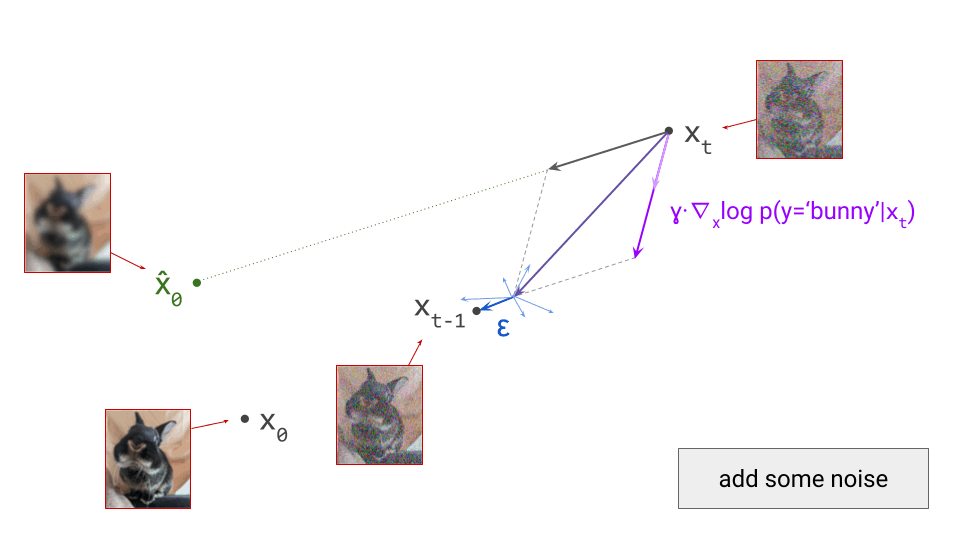
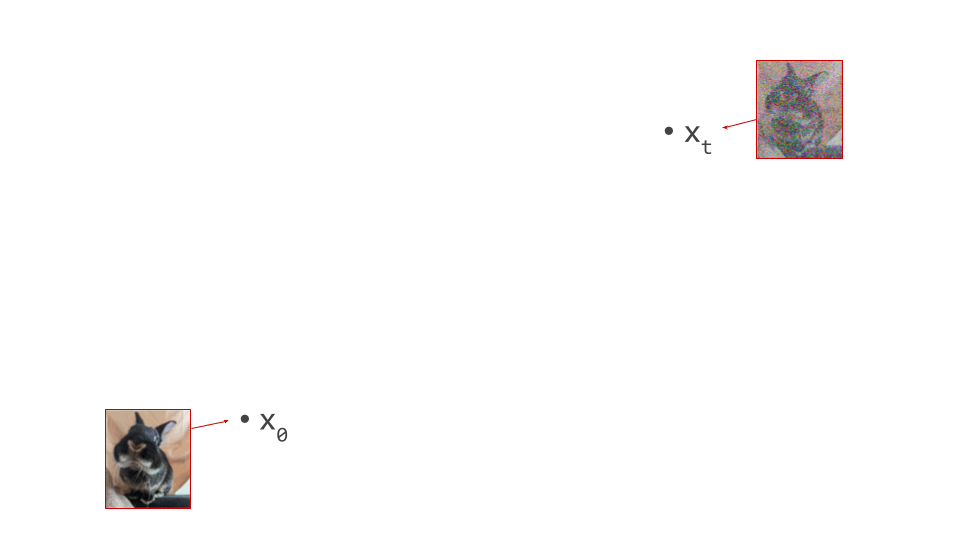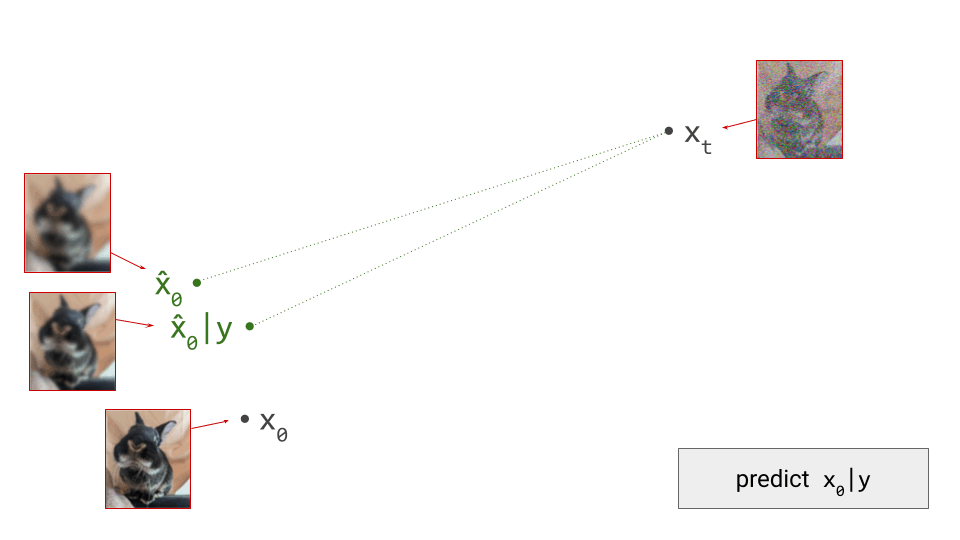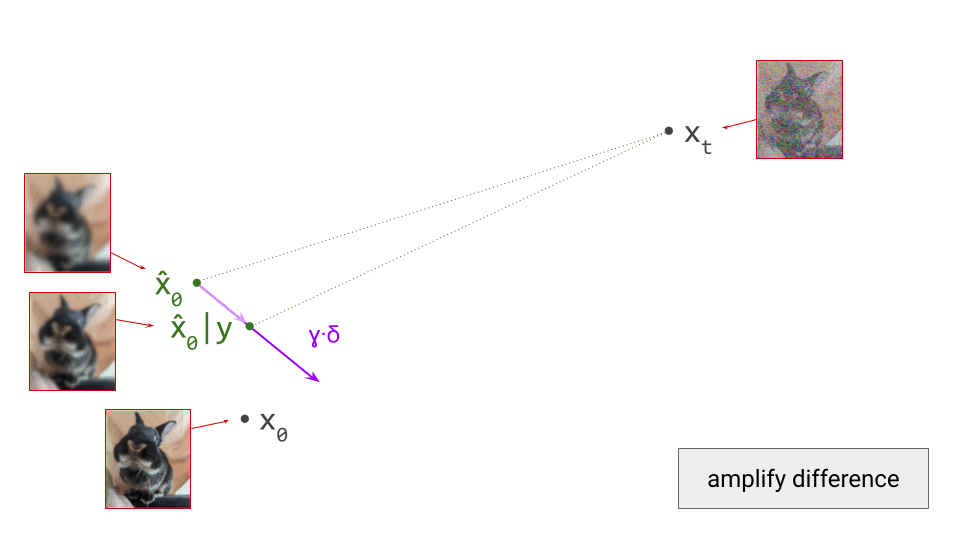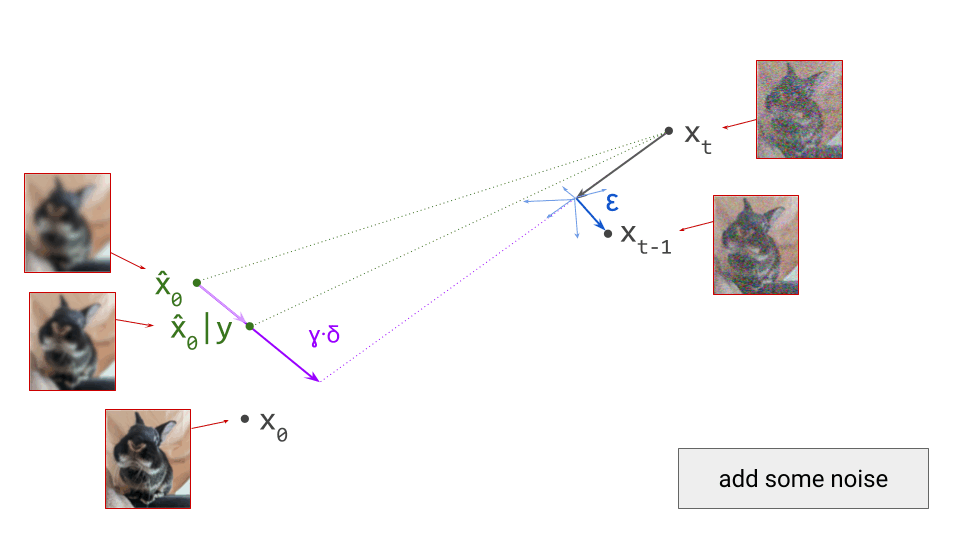
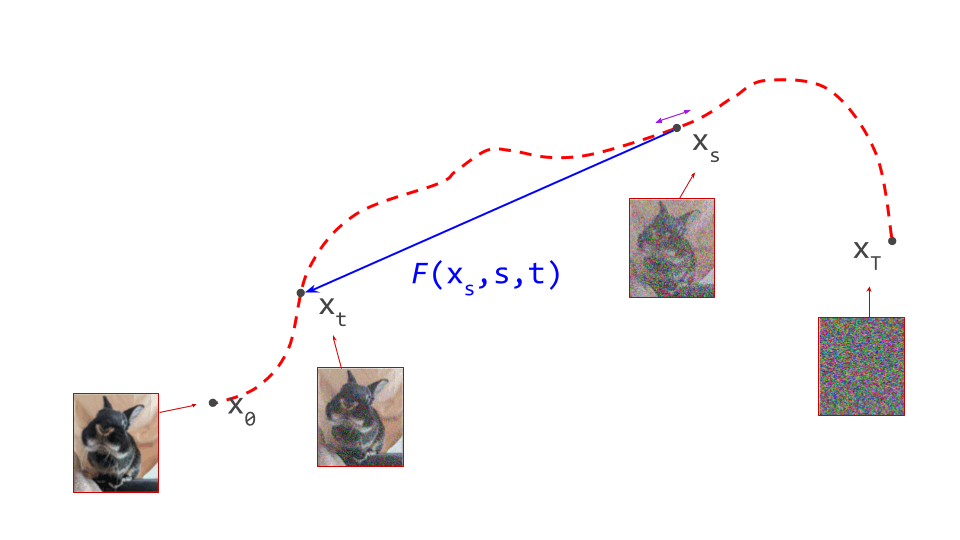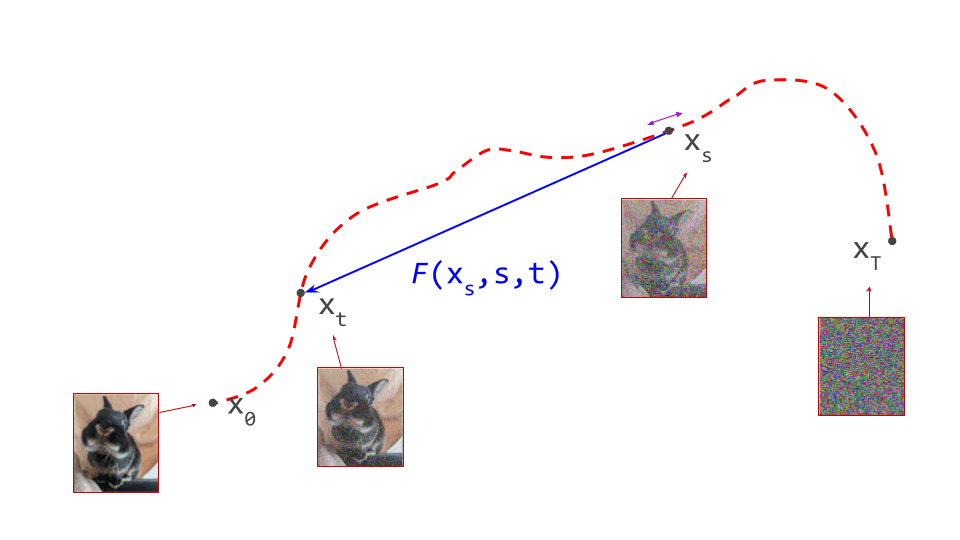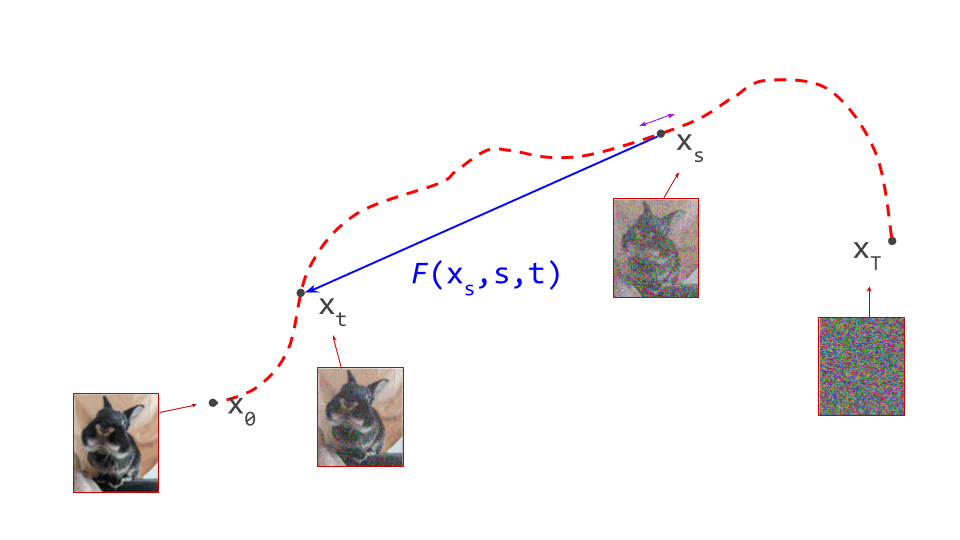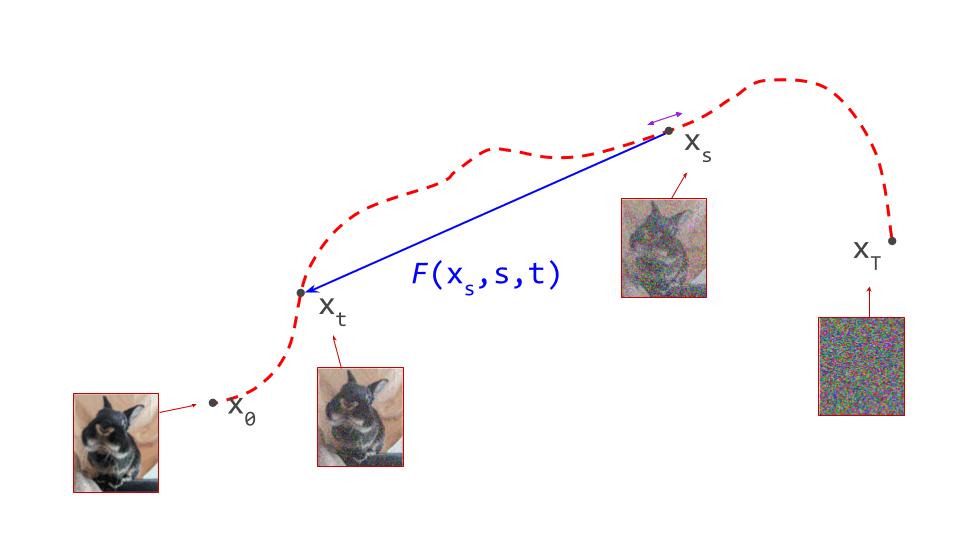
The diagram below shows a sample from the noise distribution \(\mathbf{x}_T\), the corresponding data sample \(\mathbf{x}_0\), the path through input space connecting them, and an intermediate point on the path \(\mathbf{x}_t\). It also shows the denoiser prediction \(\hat{\mathbf{x}}_0\) at this point, which corresponds to the tangent direction to the path. If you’ve read my previous posts on the geometry of guidance or distillation, you will probably be familiar with this type of diagram. The former post also contains a warning about the dangers of representing high-dimensional objects in 2D, which bears repeating: great care should be taken when drawing conclusions from 2D intuitions!
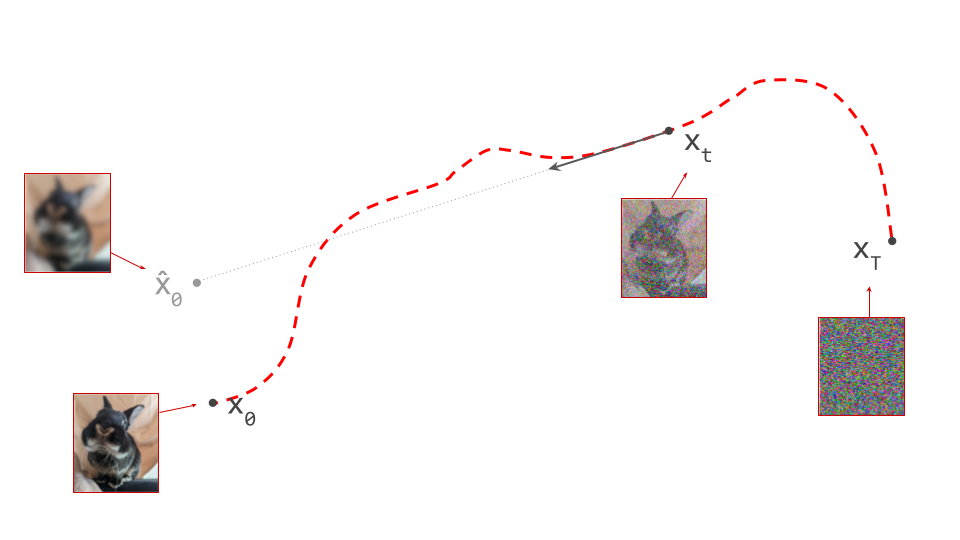
Using denoiser predictions to traverse these paths is memoryless: the only inputs to the denoiser are the current position in input space and the current noise level, from which it predicts a direction to move in, \(\hat{\mathbf{x}}_0 = f(\mathbf{x}_t, t)\). It is also myopic: the denoiser doesn’t get to peek ahead at the eventual destination \(\mathbf{x}_0\), it just says where to go next. It is not able to use any other information: no previously visited positions or previously predicted directions, no start- or endpoints, just where we are currently in the sampling process, and nothing else. This way of characterising paths brings to mind navigation through dead reckoning.
It follows that the path between a specific pair of noise and data samples that are connected in this way must be unique: if there were more than one path leading to a particular data sample, there would be multiple valid tangent directions at the point where these paths separate from each other. For the same reason, paths between different pairs of samples can never cross each other, because that would introduce ambiguity at the crossing point. It is not possible for the denoiser to distinguish between multiple crossing paths, because it only knows its current position, not which path it is on. This is shown in the diagram below.
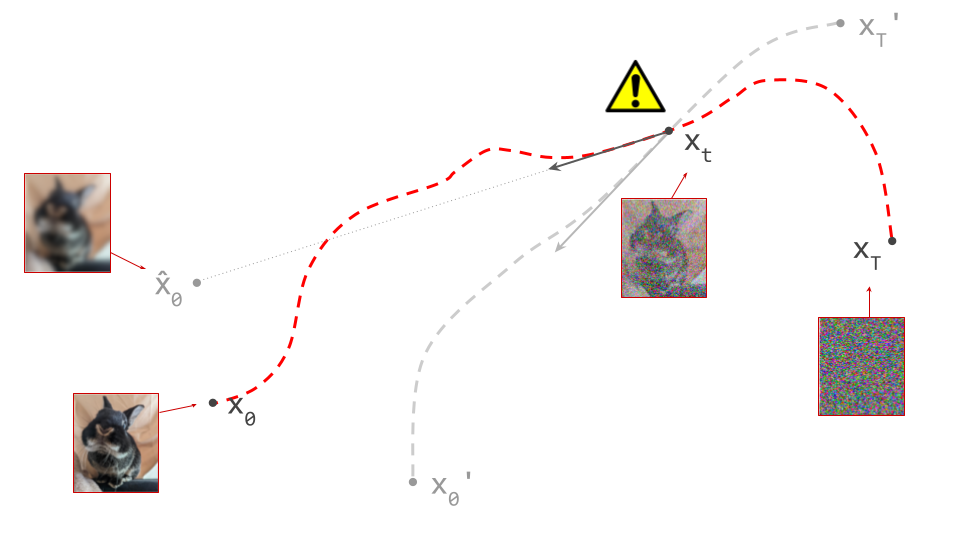
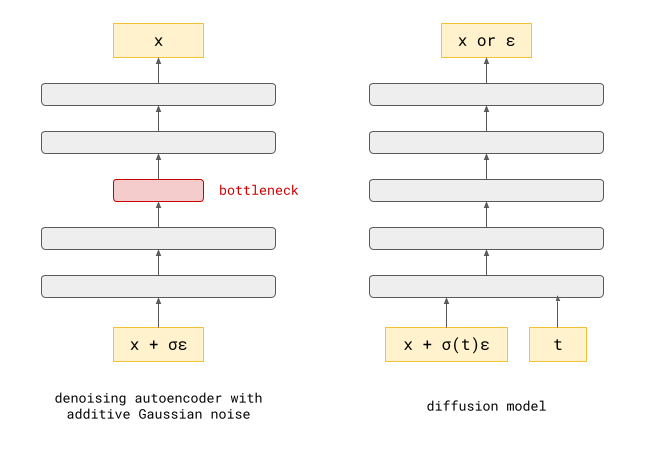
Technically, this argument only demonstrates that paths cannot cross in \((\mathbf{x}_t, t)\)-space, but they could still cross in \(\mathbf{x}_t\)-space in theory, if the two paths in question arrive at the same point in input space at different time steps \(t\). In practice, we can ignore this edge case, because the distributions of noisy intermediate samples \(p(\mathbf{x}_t)\) for two sufficiently different time steps will have basically no overlap. In fact, some recent papers8 9 suggest that not feeding the current noise level into the denoiser often works just as well or even better, because in a high-dimensional input space, it is able to infer the noise level from \(\mathbf{x}_t\) itself.
The fact that paths never cross in practice is what enables memoryless traversal using a denoiser. Paths are sometimes known as solution trajectories in the context of ODE-based sampling, because they are traversed through solving an ordinary differential equation.
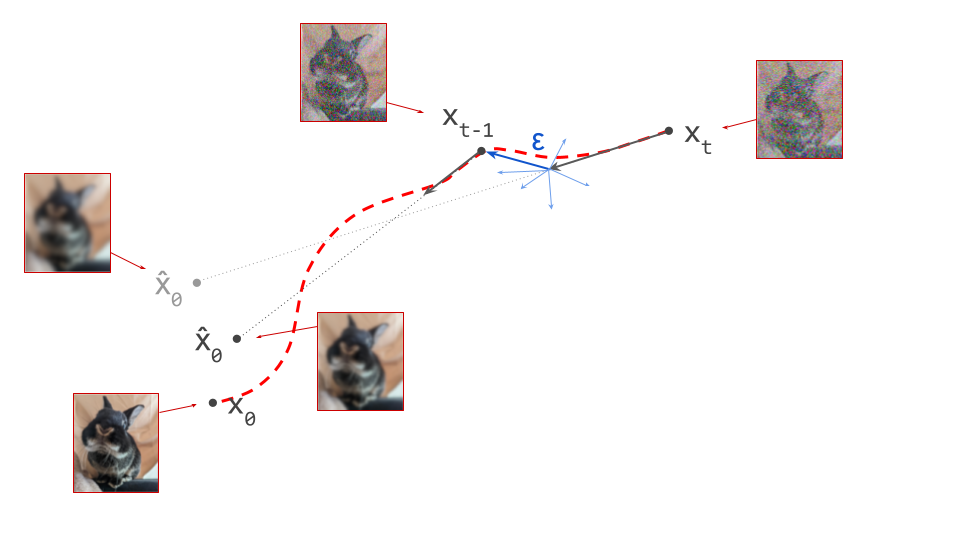
Because the paths are curved, we should ideally be taking an infinite number of infinitesimally small steps when sampling, to ensure that we don’t ‘fall off’, or end up on a different path. In practice however, we take small but finite steps, which results in approximation errors that have the potential to accumulate over the course of sampling. The quality of the approximation depends on the number of steps we take and how curved the paths are. The more curved, the more steps are needed for a good approximation.
Luckily, it is usually possible to get decent results with a computationally tractable number of steps (often less than 100). Nevertheless, people have sought to minimise path curvature to enable faster sampling. It is one of the motivations behind flow matching7 (although the degree to which it actually achieves this is hotly debated), and behind the Reflow procedure10, which ‘rewires’ the bijective mapping to obtain straighter paths by changing which data samples are connected to which noise samples.
Cartography: mapping paths with a flow map
Learning to predict the tangent direction at any point on a path using a denoiser model is a way to fully characterise that path. But it is far from the only way to achieve that goal: flow maps offer a compelling alternative1. At any point on a path, they can predict the location of any other point on that path.
Since we have already used \(f(\mathbf{x}_t, t)\) to describe a denoiser, let’s use \(F(\mathbf{x}_s, s, t)\) to describe a flow map. Note that it takes two time steps as input: \(s\) and \(t\) correspond to the source and target noise levels. Given a bijection between data and noise, the ideal flow map allows us to jump from anywhere on a path to anywhere else on that path: \(F(\mathbf{x}_s, s, t) = \mathbf{x}_t\). Usually we are interested in moving from noise towards data, so \(s > t\), but this doesn’t have to be the case. In practice, we will of course approximate this function with a neural network, just like we do with the denoiser when training a diffusion model.
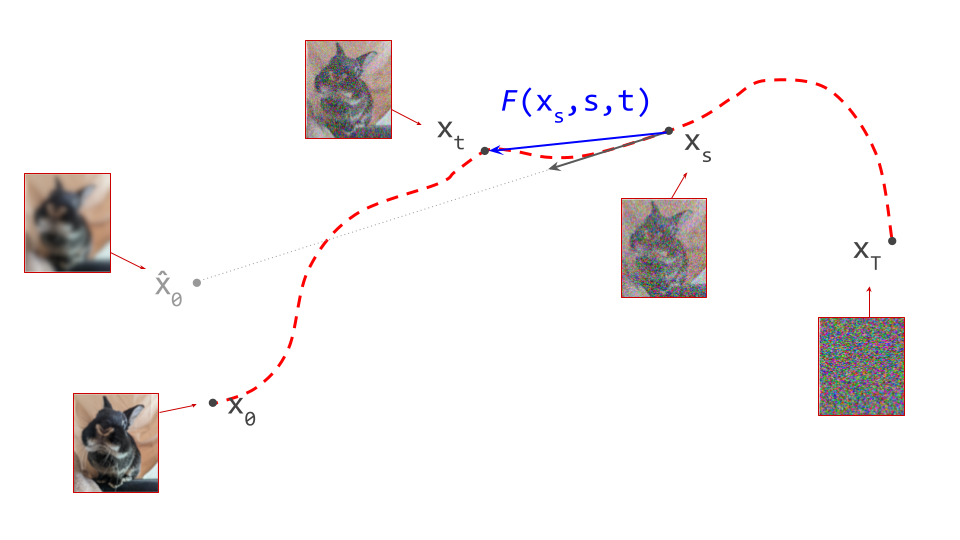
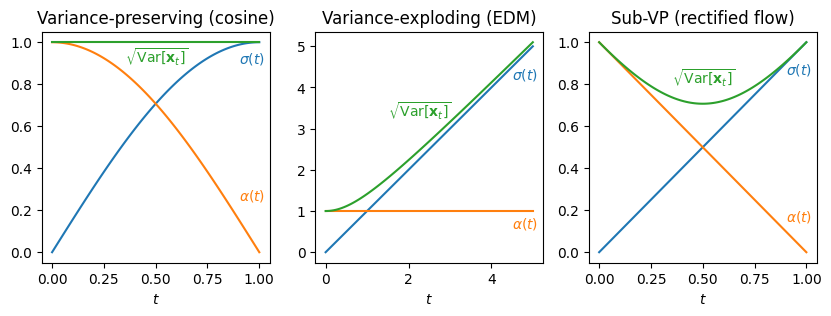
In what follows, we will assume that we use the noise schedule commonly used in flow matching: \(\mathbf{x}_t = (1 - t)\mathbf{x}_0 + t\mathbf{\varepsilon}\) and \(T=1\), with \(\mathbf{\varepsilon} \sim \mathcal{N}(0, 1)\) (standard Gaussian noise). This is arguably the most popular choice nowadays, because it keeps things simple. While it is possible to derive everything in a more general setting (assuming only \(\mathbf{x}_t = \alpha(t) \mathbf{x}_0 + \sigma(t)\mathbf{\varepsilon}\) and arbitrary \(T\)), this complicates the maths, which makes it harder to follow. Note that we will stick to the original diffusion convention for the direction of time, so \(t=0\) corresponds to the data distribution, and \(t=1\) corresponds to noise (this is the opposite of the convention used in the flow matching paper). For more on the impact of these choices, check out my blog post on noise schedules.
With these choices, given a denoiser \(f(\mathbf{x}_t, t)\), which predicts the expected clean input \(\hat{\mathbf{x}}_0 = \mathbb{E}\left[\mathbf{x}_0 \mid \mathbf{x}_t\right]\), the tangent direction to the path or velocity \(\mathbf{v}_t\) is:
\[\mathbf{v}_t = v(\mathbf{x}_t, t) = \dfrac{\mathbf{x}_t - f(\mathbf{x}_t, t)}{t} .\]In the flow matching setting, we usually parameterise the neural network to predict the function \(v(\mathbf{x}_t, t)\) directly, instead of the expected clean input, but it is easy to get one from the other (because they are linear functions of each other and \(\mathbf{x}_t\)).
A flow map can now be constructed simply by integrating the velocity over a time interval:
This integral represents taking an infinite number of infinitesimally small steps along the path, accumulating the predicted tangent direction \(v(\mathbf{x}_t, t)\) as we go. If we add this integral to the starting point \(\mathbf{x}_s\), we end up in \(\mathbf{x}_t\).
In the typical case where we go from noise to data, \(s > t\), because \(t = 0\) corresponds to the data side in the diffusion convention, which makes the lower integration bound in this formula higher than the upper bound. This reflects how diffusion is defined in terms of a forward corruption process, and sampling from the data distribution actually means going backward. We defined \(\mathbf{v}_t\) to point from \(\hat{\mathbf{x}}_0\) towards \(\mathbf{x}_t\) by convention, so we want to follow this vector in the opposite direction to move towards the data side.
Some special cases are worth highlighting:
-
If we set \(t=0\), we can directly jump from anywhere on the path to its end point at the data side: \(F(\mathbf{x}_s, s, 0) = \mathbf{x}_0\). Provided we can do this accurately, this enables sampling in a single step. This is precisely what consistency models11 do. Flow maps are a generalisation of that idea, and we’ll discuss this connection in more detail later on.
-
If we set \(s=t\), the interval over which we integrate has length zero, so the integral itself is zero, and therefore \(F(\mathbf{x}_t, t, t) = \mathbf{x}_t\).
-
Although we are usually interested in traversing paths from noise to data, which implies \(t < s\), this does not have to be the case. We can use the same formulas to go in the other direction, by choosing \(t > s\). As an example, \(F(\mathbf{x}_s, s, 1)\) predicts the end point at the noise side of the path containing \(\mathbf{x}_s\).
Hopefully it is obvious that learning to predict the function \(F(\mathbf{x}_s, s, t)\) with a neural network is a harder task than learning to predict \(f(\mathbf{x}_t, t)\) – not least because it has two time step inputs instead of one. It provides a global characterisation of the paths between data and noise samples, rather than a strictly local one. This can also be much more practical: once we have a flow map, we don’t need to worry anymore about taking small enough steps during sampling to avoid falling off the path. In fact, if our neural network approximation is good enough, we can just sample noise \(\mathbf{\varepsilon}\) and take a single step, \(F(\mathbf{\varepsilon}, 1, 0)\) directly from \(s=1\) to \(t=0\) to arrive at \(\mathbf{x}_0\), and we’re done sampling! In the next section, we will discuss how to train flow map models.
Just like it is common to parameterise diffusion models to predict either the expected clean input \(\hat{\mathbf{x}}_0\) or the velocity \(\mathbf{v}_t\), there are two equivalent parameterisations for flow maps. The one we have described so far, \(F(\mathbf{x}_s, s, t)\), predicts the destination on the path, but we can also predict the average velocity or mean flow along the path12:
The relation between the two parameterisations is:
\[F(\mathbf{x}_s, s, t) = \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) .\]Here, the limiting case \(s = t\) yields \(V(\mathbf{x}_t, t, t) = v(\mathbf{x}_t, t)\): the average velocity over a length-zero interval is simply the instantaneous velocity. This shows that a flow map contains within it a denoiser, and therefore it can also be used as a standard diffusion model.
Given that it is possible to construct flow maps, one might be led to believe that they make diffusion models obsolete. The former are a strict generalisation of the latter, and the global view of paths between data and noise samples that they provide has many practical benefits. But as we will see, all the approaches that have been developed so far to construct this global view, work by bootstrapping from the local view provided by diffusion models. Sometimes this relationship is explicit, and sometimes it is less obvious, but it is always there. As ever in machine learning, there is no free lunch: while sampling using a flow map is cheaper than sampling from a diffusion model, training a flow map is significantly more involved, and often requires training a diffusion model first. Just like drawing an accurate map makes navigation a lot easier, but requires a lot more work up front!
Three notions of consistency

A flurry of different algorithms have been proposed to train flow maps. It turns out all these variants are ultimately based on one of three closely related consistency rules: compositionality, Lagrangian consistency and Eulerian consistency. In this section, we will cover each of these in turn, and then discuss how we can use them for flow map training.
Boffi, Albergo and Vanden-Eijnden originally developed the flow map framework and described these three rules (and training procedures derived from them) in two recent papers on flow map matching1 and self-distillation2. Although their work is rooted in the ‘stochastic interpolant’ perspective, I will not adopt this here and stick with a more traditional diffusion framing instead, as I believe more people are familiar with that.
Compositionality
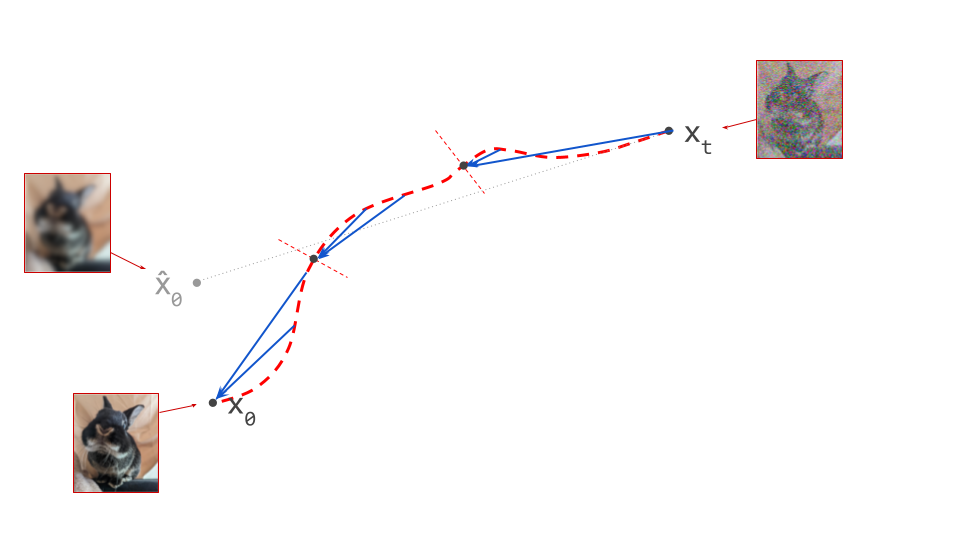
The flow map \(F(\mathbf{x}_s, s, t)\) allows us to travel directly from \(\mathbf{x}_s\) on the path to \(\mathbf{x}_t\) on the same path. We can repeat the same procedure to travel farther along the path from there, using \(F(\mathbf{x}_t, t, u)\) to take us to \(\mathbf{x}_u\). But we could also have got there in one step, using \(F(\mathbf{x}_s, s, u)\). Either way of traversing the path should yield the same result:
In other words, flow maps are compositional. This is what I’m calling this property – it is a nonstandard term. I’m being stubborn about this, because I find the various names used in the literature to be ambiguous and confusing. You’ll see this called the ‘semigroup property’, the ‘shortcut property’, or ‘progressive matching / distillation’.
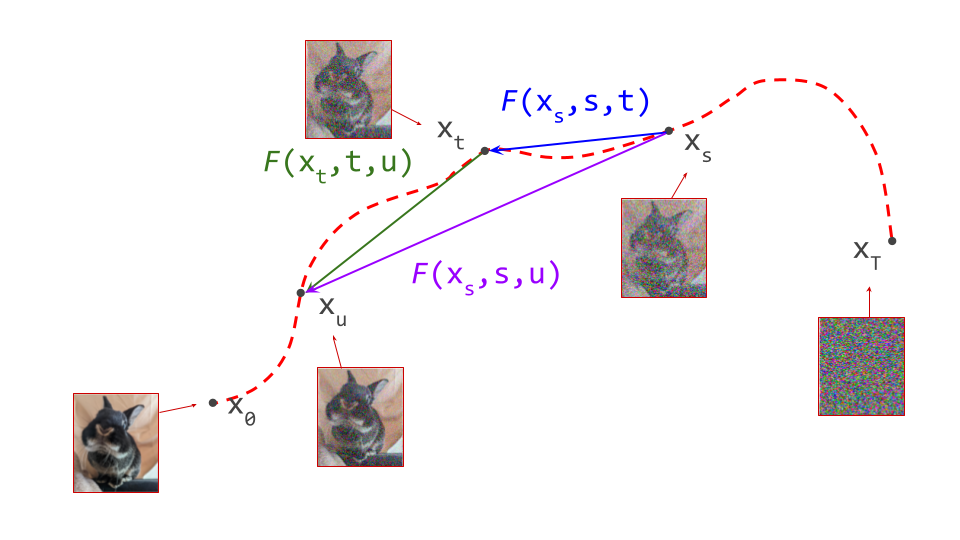
A corollary is that a flow map is its own inverse (with regards to its first argument):
\[F(F(\mathbf{x}_s, s, t), t, s) = \mathbf{x}_s .\]In this case, we’ve assumed that the flow map is defined for both \(s > t\) and \(t > s\). Very often however, flow maps are only trained in one direction (\(s > t\), from high noise levels to low noise levels), because that is the relevant direction for sampling (moving towards the data distribution).
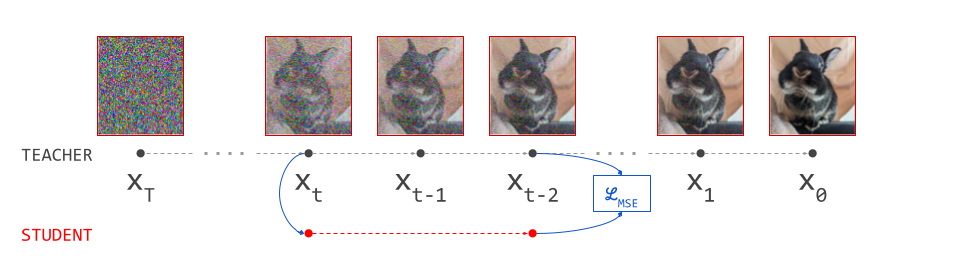
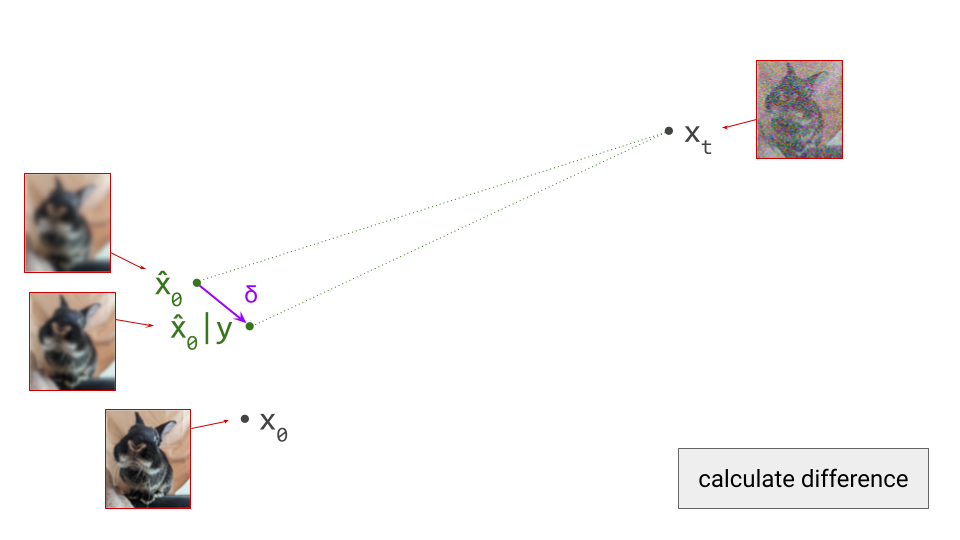
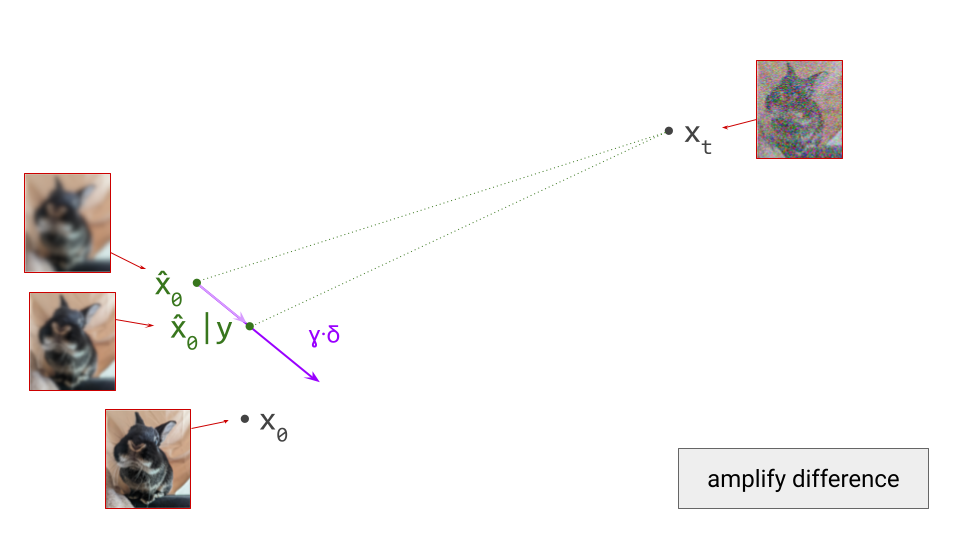
We can use compositionality to train a flow map by bootstrapping from a diffusion model. We start at \(\mathbf{x}_s\) and use the diffusion model to predict the next point on the path \(\mathbf{x}_t\), a short distance ahead. We can then use the fact that the flow map should always give the same answer, regardless of the starting point: \(F(\mathbf{x}_s, s, u) = F(\mathbf{x}_t, t, u)\), and as a special case, for \(t = u\): \(F(\mathbf{x}_s, s, t) = F(\mathbf{x}_t, t, t)\). By ensuring these equalities hold, we can transport information about the flow from smaller time intervals to larger time intervals.

The Lagrangian perspective: moving the goalposts
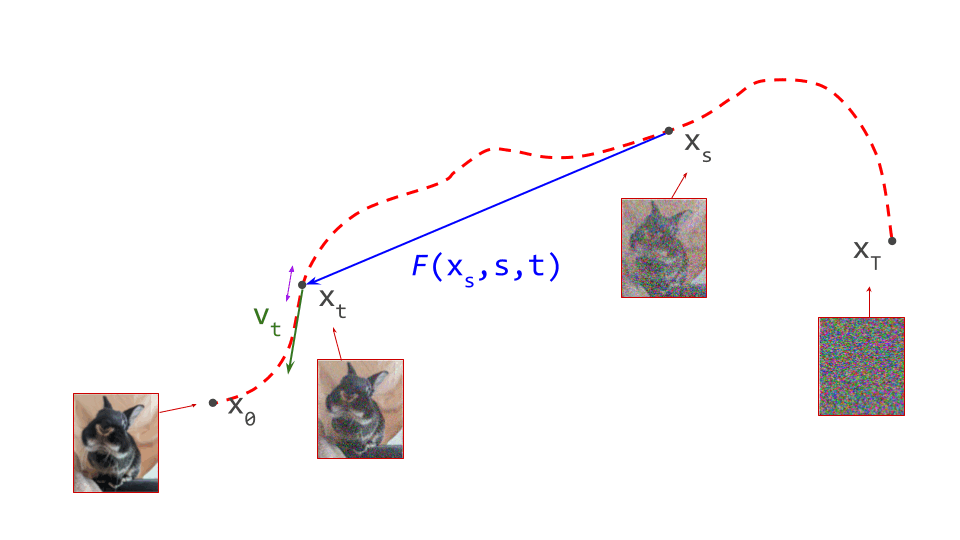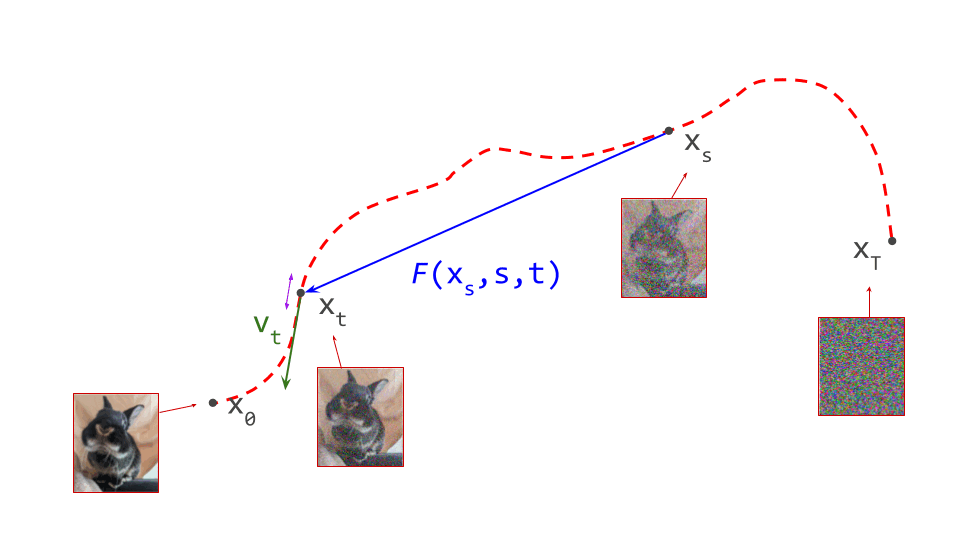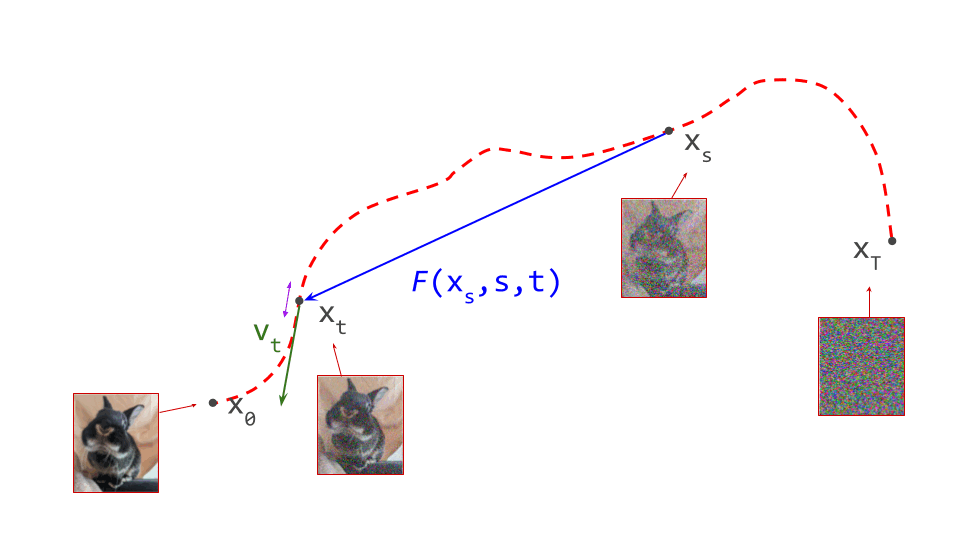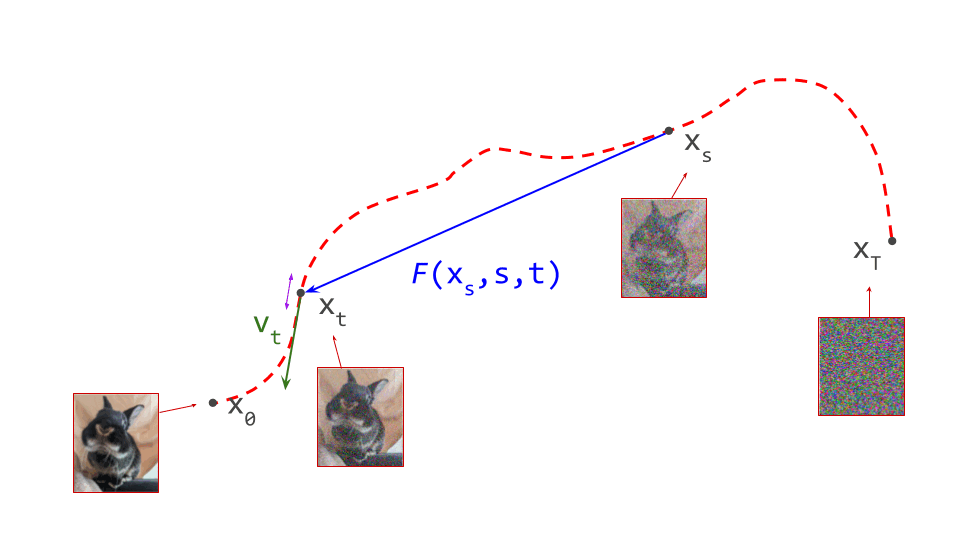
Another way to characterise the consistency of a flow map \(F(\mathbf{x}_s, s, t)\) is to study how its output changes as we gradually change \(t\), which indexes the destination (i.e. move the goalposts). This should result in the output \(\mathbf{x}_t\) travelling along the path. If we consider an infinitesimal change to \(t\), we can characterise what happens using the derivative:
\[\dfrac{\mathrm{d}}{\mathrm{d} t} F(\mathbf{x}_s, s, t) = \dfrac{\mathrm{d}\mathbf{x}_t}{\mathrm{d} t} = \mathbf{v}_t .\]In other words: the instantaneous change in the output of the flow map is the velocity. Intuitively this makes sense, as changing \(t\) means we are simply traversing the path, and the velocity is precisely the direction we should travel in to follow that trajectory.
We can expand the velocity \(\mathbf{v}_t = v(\mathbf{x}_t, t) = v(F(\mathbf{x}_s, s, t), t)\), and this gives us another way to bootstrap flow map learning from a diffusion model \(v(\mathbf{x}_t, t)\). We must simply ensure that the following equality holds everywhere:
where we have used that the total derivative of the flow map w.r.t. \(t\) is equal to the partial derivative, because the other arguments do not depend on \(t\): \(\frac{\mathrm{d}F}{\mathrm{d}t} = \frac{\partial F}{\partial t}\).
Another way of interpreting Lagrangian consistency is that it is just a special case of compositionality, where we have shrunk the second time interval to be infinitesimal: we let \(t \rightarrow u\) and look at the limiting behaviour. Let’s take the compositionality rule and replace \(u\) by \(t + \Delta t\) to make this more explicit:
\[F(F(\mathbf{x}_s, s, t), t, t + \Delta t) = F(\mathbf{x}_s, s, t + \Delta t) .\]This equation is also true when \(\Delta t = 0\):
\[F(F(\mathbf{x}_s, s, t), t, t) = F(\mathbf{x}_s, s, t) .\]Subtracting this special case from the original equation, and dividing by \(\Delta t\), we get:
\[\dfrac{F(F(\mathbf{x}_s, s, t), t, t + \Delta t) - F(F(\mathbf{x}_s, s, t), t, t)}{\Delta t} = \dfrac{F(\mathbf{x}_s, s, t + \Delta t) - F(\mathbf{x}_s, s, t)}{\Delta t} .\]Finally, we take the limit as \(\Delta t \rightarrow 0\), and use the definition of the derivative:
\[\left. \dfrac{\mathrm{d}}{\mathrm{d} u} F(F(\mathbf{x}_s, s, t), t, u) \right\vert_{u=t} = \dfrac{\mathrm{d}}{\mathrm{d} t} F(\mathbf{x}_s, s, t) .\]To simplify the left hand side, we recall the original flow map definition, \(F(\mathbf{x}_s, s, t) = \mathbf{x}_s + \int_s^t v(\mathbf{x}_\tau, \tau) \mathrm{d} \tau\), and take the corresponding derivative:
\[\dfrac{\mathrm{d}}{\mathrm{d} t} F(\mathbf{x}_s, s, t) = \dfrac{\mathrm{d}}{\mathrm{d} t} \left( \mathbf{x}_s + \int_s^t v(\mathbf{x}_\tau, \tau) \mathrm{d} \tau \right) = v(\mathbf{x}_t, t) ,\]where we have used that \(\frac{\mathrm{d}}{\mathrm{d}t} \mathbf{x}_s = 0\), and the fundamental theorem of calculus. Applying this simplification, we once again find:
\[v(F(\mathbf{x}_s, s, t), t) = \dfrac{\partial}{\partial t} F(\mathbf{x}_s, s, t) .\]
The Eulerian perspective: eyes on the prize
Instead of looking at the impact of changing the target time step \(t\), we can also study what happens when \(s\) changes, i.e. the starting point. At first glance, this looks even simpler:
\[\dfrac{\mathrm{d}}{\mathrm{d} s} F(\mathbf{x}_s, s, t) = 0 .\]When we change the starting point, but the target time step \(t\) remains the same, the destination should not change at all. Therefore, its derivative must be zero. Easy enough, right? This apparent simplicity is deceptive, however. We now have two inputs that depend on \(s\): the source time step \(s\), and also our actual starting position in the input space, \(\mathbf{x}_s\).
Because two of our three function inputs now depend on \(s\), we need to use the multivariate chain rule to work this out:
\[\dfrac{\mathrm{d}}{\mathrm{d} s} F(\mathbf{x}_s, s, t) = \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t) \dfrac{\mathrm{d} \mathbf{x}_s}{\mathrm{d}s} + \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, t) = 0.\]This is basically a combination of two changes: the change in the input space resulting from the change to the starting time step \(s\), and the change to the starting time step itself.
We note that \(\frac{\mathrm{d} \mathbf{x}_s}{\mathrm{d}s} = v(\mathbf{x}_s, s) = \mathbf{v}_s\), and obtain yet another equality that enables us to bootstrap flow map learning from a diffusion model, by ensuring it holds everywhere:
As with Lagrangian consistency, we can interpret Eulerian consistency as a special case of compositionality. This time, we shrink the first time interval to be infinitesimal instead, letting \(s \rightarrow t\). Let’s recap the compositionality rule one more time, and substitute \(t\) with \(s + \Delta s\):
\[F(F(\mathbf{x}_s, s, s + \Delta s), s + \Delta s, u) = F(\mathbf{x}_s, s, u) .\]Because \(\Delta s\) is very small, we can use the following approximation:
\[F(\mathbf{x}_s, s, s + \Delta s) = \mathbf{x}_s + \int_s^{s + \Delta s} v(\mathbf{x}_\tau, \tau) \mathrm{d} \tau \approx \mathbf{x}_s + v(\mathbf{x}_s, s) \Delta s,\]where we have assumed that \(v(\mathbf{x}_\tau, \tau)\) remains constant over the integration interval. Since we plan to let \(\Delta s \rightarrow 0\), this is a valid assumption. We now have:
\[F(\mathbf{x}_s + v(\mathbf{x}_s, s)\Delta s, s + \Delta s, u) = F(\mathbf{x}_s, s, u) .\]We now perform a first-order multivariate Taylor expansion around \((\mathbf{x}_s, s)\) on the left hand side, to get:
\[F(\mathbf{x}_s, s, u) + \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, u) v(\mathbf{x}_s, s)\Delta s + \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, u) \Delta s .\]Note that \(F(\mathbf{x}_s, s, u)\) appears as the first term, and also on the right hand side of our previous equation, so these cancel out. We are left with:
\[\nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, u) v(\mathbf{x}_s, s)\Delta s + \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, u) \Delta s = 0 .\]Now just divide out \(\Delta s\) to recover the Eulerian consistency rule:
\[\dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, u) + \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, u) v(\mathbf{x}_s, s) = 0.\]Although we didn’t explicitly take a limit \(\Delta s \rightarrow 0\) anywhere, we did rely on approximations that are only valid when it is very small.

Eulerian and Lagrangian consistency are ultimately just different perspectives of the same thing, using different reference frames. For Lagrangian consistency, we focus on a specific noisy input example, and track how the flow map’s output evolves over time. For Eulerian consistency, we fix the target time step and assess how things change as the input changes. If the flow is a river, it’s basically the difference between sitting in a canoe, following its path (Lagrangian), and standing on a bridge, looking down (Eulerian).
Constructing loss functions from equalities
The equations describing these three consistency rules can feel somewhat tautological, almost trivial even: it is clear that they must be true for any valid flow map. But neural networks are flexible enough to learn almost any function of three inputs, \(\mathbf{x}_s\), \(s\) and \(t\), and most of these possibilities will not be consistent in the way that a valid flow map should be. When learning a flow map, it is therefore useful to explicitly enforce the consistency rules.
It turns out that any of them will do: if a function adheres to any of the three consistency rules we have just discussed, in combination with the right boundary conditions, it is automatically a valid flow map. This actually gives us a lot of options for constructing loss functions to train flow maps with.
The consistency rules are all equalities. Turning these into loss functions is pretty straightforward: move all terms over to the left hand side, so that the right hand side is zero. The left hand side is now a residual, which measures how far away we are from achieving consistency. Then, simply penalise the residual, so that it ends up as close to zero as possible when the loss is minimised. The most straightforward way to achieve that is to simply square the left hand side, and average over all possible time step combinations (and the training dataset) to obtain a loss function.
For the three consistency rules, we get, respectively:
\[\mathcal{L}_{\mathrm{compositional}} = \mathbb{E} \left[ \left( F(F(\mathbf{x}_s, s, t), t, u) - F(\mathbf{x}_s, s, u) \right)^2 \right],\] \[\mathcal{L}_{\mathrm{Lagrangian}} = \mathbb{E} \left[ \left( \frac{\partial}{\partial t} F(\mathbf{x}_s, s, t) - v(F(\mathbf{x}_s, s, t), t) \right)^2 \right],\] \[\mathcal{L}_{\mathrm{Eulerian}} = \mathbb{E} \left[ \left( \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right)^2 \right].\]The minima of all three of these loss functions guarantee consistency. Even if we cannot perfectly minimise these functions in practice, we can usually get close enough for things to work as expected.
To learn something useful, we constrain \(F(\mathbf{x}_t, t, t) = \mathbf{x}_t\), and ensure that \(v(\mathbf{x}_t, t)\) corresponds to a meaningful velocity. This can be achieved by first training a diffusion model and using that as a reference (i.e. distillation), but there are also other ways to constrain the implied velocity, which enable training flow maps from scratch (see section 4).
Note that squaring the residual is an arbitrary choice, to some extent. We could also penalise its absolute value, or use something more exotic like the Huber loss. In some cases, as we will see later, we can even use the categorical cross-entropy. The mean squared error (MSE) approach has some practical advantages though: it is relatively easy to optimise by gradient descent, and essential for some from-scratch training methods to work (see section 4.2).
To backprop or not to backprop?

Taking a closer look at these loss functions, there are are some things that are bit unusual about them:
- two of them contain derivatives of the function \(F\) that we are trying to learn (Lagrangian and Eulerian). This implies that gradient-based learning could potentially involve higher-order derivatives.
- the other variant involves multiple sequential applications of \(F\), potentially requiring sequential forward and backward passes during training.
Unlike most loss functions used in machine learning, which measure the difference between a model prediction and a static target (the ‘ground truth’), these ones involve moving targets and are self-referential. In theory, gradient-based optimisation doesn’t care about this: it just tries to find an optimum of whatever function you throw at it (usually a local optimum). But by casting flow map training into this more traditional machine learning framework with static targets, we can actually overcome some hurdles, like avoiding having to calculate higher-order derivatives.
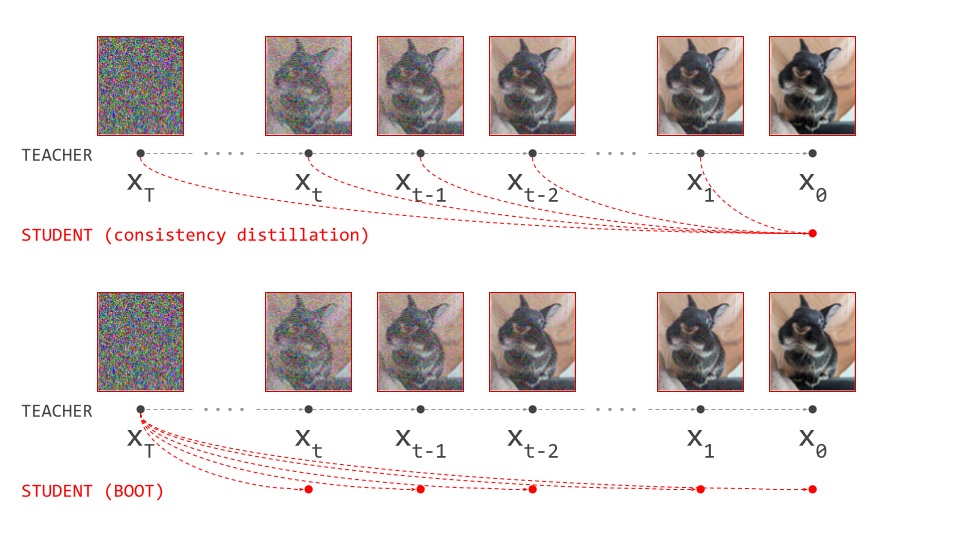
Stemming the flow (of gradients)
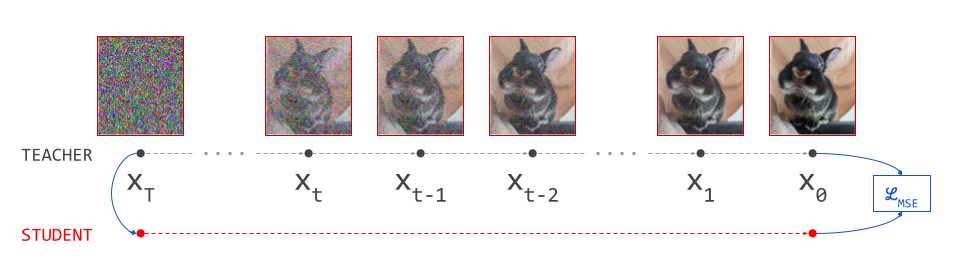
We can take inspiration from representation learning, where these types of self-referential loss functions with moving targets have become increasingly common13 14. Here, one network learns to mimic the output of another, like the student and teacher in distillation. The teacher is constructed using the same parameters as the student. Often, an exponential moving average (EMA) of the parameters is used, and no gradients are backpropagated through the teacher side of the loss, which helps avoid collapse to a degenerate solution.
The same kind of tricks can be used to stabilise and simplify flow map training. We can wrap portions of the loss in a stop-gradient operation. This blocks gradient flow during backpropagation, and acts as a pass-through otherwise:
\[\mathcal{L}_{\mathrm{Lagrangian}} = \mathbb{E} \left[ \left( \frac{\partial}{\partial t} F(\mathbf{x}_s, s, t) - v(\mathrm{sg} \left[ F(\mathbf{x}_s, s, t) \right], t) \right)^2 \right],\] \[\mathcal{L}_{\mathrm{Eulerian}} = \mathbb{E} \left[ \left( \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, t) + \mathrm{sg} \left[ \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right] \right)^2 \right],\]where \(\mathrm{sg}[\cdot]\) indicates the stop-gradient operation. Anything that is wrapped inside will be treated as constant for the purpose of backpropagation, so we avoid having to backpropagate through \(\nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t)\), for example. Similarly in the compositional case, we can use a stop-gradient operation to avoid sequential backward passes:
\[\mathcal{L}_{\mathrm{compositional}} = \mathbb{E} \left[ \left( \mathrm{sg} \left[ F(F(\mathbf{x}_s, s, t), t, u) \right] - F(\mathbf{x}_s, s, u) \right)^2 \right].\]This has an elegant interpretation: we calculate a target using two sequential flow map steps, treat it as ground truth and freeze it, and then update the flow map to learn how to get there in one step.
Since any part of the loss wrapped inside a stop-gradient operation is effectively treated as static (even if it technically isn’t), we can sometimes stabilise training by using EMA parameters to calculate it. This ensures that it varies more slowly over the course of training, which makes the implicit assumption that it is static less egregious.
Introducing the stop-gradient operation has an interesting implication: the ‘gradient’ direction calculated by backpropagating only through part of the loss, is not actually a gradient direction! At least, it is not the gradient direction of the loss that we are trying to optimise – it could still be a valid gradient for another loss function, for all we know. It is sometimes referred to as a semigradient2. This means that some theoretical guarantees about gradient-based optimisation go out of the window. Luckily, when done with care, abandoning the safety of theoretical grounding does not seem to cause any major problems in practice (as is so often the case with neural networks), but it is worth being aware of.
The loss variants given above are just examples: exactly which parts of the loss expressions are wrapped in stop-gradient operations, or are stabilised by using EMA parameters, is what distinguishes various flavours of flow map training. We will explore this design space extensively in section 5.
The ‘average velocity’ perspective
At this point, it is useful to recall the average velocity parameterisation of flow maps, which we previously discussed in section 1.3. This is because it interacts in interesting ways with the derivatives in the Lagrangian and Eulerian consistency rules:
\[V(\mathbf{x}_s, s, t) = \dfrac{1}{t - s} \int_s^t v(\mathbf{x}_\tau, \tau) \mathrm{d} \tau ,\] \[F(\mathbf{x}_s, s, t) = \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) .\]We can express the Lagrangian consistency rule in terms of \(V\) by substitution:
\[\frac{\partial}{\partial t} \left( \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) \right) = v( F(\mathbf{x}_s, s, t), t) .\]We have not performed the substitution for the first argument of \(v\), as this would not allow us to simplify anything anyway. Now we can work out the time derivative on the left hand side, which requires the product rule:
\[\frac{\partial}{\partial t} \left( \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) \right) = V(\mathbf{x}_s, s, t) + (t - s) \dfrac{\partial}{\partial t} V(\mathbf{x}_s, s, t) .\]Note how in addition to its time derivative, \(V\) itself appears in this expression. Rearranging the terms to isolate \(V\), we get:
\[V(\mathbf{x}_s, s, t) = v( F(\mathbf{x}_s, s, t), t) - (t - s) \dfrac{\partial}{\partial t} V(\mathbf{x}_s, s, t) .\]We can interpret this as follows: the average velocity over the time interval between \(s\) and \(t\) is the velocity at the endpoint, minus a correction term involving the derivative of the average velocity itself w.r.t. the target time step \(t\). When we use this expression to construct a loss, we can wrap the entire right hand side in a stop-gradient operation. That means we don’t have to worry about backpropagating through the time derivative, and no higher-order differentiation is needed to optimise the loss.
We can do the exact same thing with the Eulerian consistency rule:
\[\dfrac{\partial}{\partial s} \left( \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) \right) + \nabla_{\mathbf{x}_s} \left( \mathbf{x}_s + (t - s) V(\mathbf{x}_s, s, t) \right) v(\mathbf{x}_s, s) = 0.\]Using the product rule (twice), we get:
\[- V(\mathbf{x}_s, s, t) + (t - s) \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + v(\mathbf{x}_s, s) + (t - s) \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) = 0.\]Rearranging to isolate \(V\), we get:
\[V(\mathbf{x}_s, s, t) = v(\mathbf{x}_s, s) + (t - s) \left( \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right) .\]This expresses the average velocity as the velocity at the starting point, plus a correction term involving the derivative of the average velocity itself w.r.t. the source time step \(s\). We can once again wrap the entire right hand side in a stop-gradient operation, which forms the basis of MeanFlow12:
\[\mathcal{L}_\mathrm{MF} = \\ \mathbb{E} \left[ \left( V(\mathbf{x}_s, s, t) - \mathrm{sg} \left[ v(\mathbf{x}_s, s) + (t - s) \left( \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right) \right] \right)^2 \right] .\]Forward- and reverse-mode differentiation
Modern frameworks for neural network training calculate gradients for you, so you rarely need to worry about them, but the automatic differentiation machinery that makes this possible is quite intricate.
To calculate gradients for a deep computation graph, there are two main methods: forward-mode and reverse-mode differentiation. They traverse the graph from input to output, and from output to input respectively. The choice between them comes down to the dimensionality of the input and output: if the output is higher-dimensional than the input, forward mode is more efficient. In the other case, reverse mode wins out. When training a neural network, the input is usually high-dimensional, but the ultimate output of the computation graph we are differentiating is almost invariably a single loss value. That is a scalar, so the output dimensionality is much lower than the input dimensionality, and reverse mode is the right choice. This is what these frameworks will use by default.
Forward mode does make an occasional appearance, though; it can be used to efficiently compute Jacobian-vector products (JVPs). Such a product occurs in the Eulerian consistency rule:
\[\dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) = \left[ \dfrac{\partial V}{\partial \mathbf{x}_s} , \dfrac{\partial V}{\partial s} , \dfrac{\partial V}{\partial t} \right] \left[ v, 1, 0 \right] .\]The Jacobian of \(V\), which consists of all its partial derivatives, is multiplied by the so-called tangent vector \([v, 1, 0]\). In JAX, we can use jax.jvp to calculate this. It efficiently computes both the forward pass and the derivative at the same time, and avoids explicitly materialising the full Jacobian matrix in memory. That’s not a luxury, because it is massive: \(V\) has the same shape as \(\mathbf{x}_s\), so if they are both vectors of size \(K\), then \(\frac{\partial V}{\partial \mathbf{x}_s}\) is a \(K \times K\) matrix!
Finite-difference approximations
Instead of stopping gradient flow altogether, another common trick to avoid dealing with derivatives is to replace them with finite-difference approximations. We can use the definition of the derivative:
\[\dfrac{\mathrm{d}}{\mathrm{d}x} f(x) = \lim_{h \rightarrow 0} \dfrac{f(x + h) - f(x)}{h} \approx \dfrac{f(x + \Delta x) - f(x)}{\Delta x} .\]Here, \(\Delta x\) is the finite difference. As long as it is small, the approximation can be quite good. Small values are prone to causing issues with floating point precision (especially nowadays, with low-precision neural network training being highly in vogue), so care needs to be taken when using this approach.
Remember how we derived the Lagrangian and Eulerian consistency rules from the compositionality rule by shrinking one of the time intervals to be infinitesimal? Applying a finite difference approximation to either of them would effectively make that interval finite again. This can make classification of methods according to the consistency rule they are based on somewhat ambiguous.
Practical considerations
It is worth asking if we really need all this mucking about with gradients. Why is it a problem to just backpropagate through everything? Modern frameworks certainly make it possible and even easy in the vast majority of cases, but that doesn’t mean it is always a good idea:
-
Calculating higher-order derivatives can be costly, in terms of the number of floating point operations (FLOPS), but also and especially in terms of memory. It often involves keeping around large tensors for a long time, because they get reused in multiple places in the computation graph.
-
Usually, higher-order derivatives of modern neural networks are not very meaningful. The second order derivative captures curvature, which often doesn’t vary smoothly across the input space. As an extreme example, a network with only ReLU nonlinearities is effectively piecewise linear, so its curvature is zero almost everywhere. This is also why we don’t typically parameterise diffusion models as the gradient of a scalar energy function, even though we definitely could15.
-
More and more often, we use specialised fast kernels for certain operations (e.g. FlashAttention16). These tend to come with an equally efficient implementation of the backward pass, to support training. Forward-mode differentiation and higher-order derivatives usually aren’t implemented, requiring fallback to slower implementations.
Different implementations of flow map training will require different numbers of forward and backward passes for each training iteration (e.g. a finite difference approximation usually replaces a backward pass with two forward passes), and may or may not require forward-mode differentiation or higher-order derivatives. A notable case is Terminal Velocity Matching17 (TVM), an implementation based on Lagrangian consistency which does not make use of stop-gradient operations or any other approximations to avoid higher-order derivatives. The authors explicitly mention developing a custom attention kernel to support this. We will discuss various implementations in more detail in section 5.
Training flow maps from scratch
Building a flow map to describe paths between noise and data samples requires some form of bootstrapping: for example, training a diffusion model provides us with the velocity \(v(\mathbf{x}_t, t)\), which is by itself sufficient to completely describe said paths. We can then use that as a starting point for flow map training, which effectively turns it into a form of distillation.
But what if we want to train a flow map from scratch? There are many good reasons to prefer a single-stage training process. Any sequential dependency adds a great deal of complexity, which we should only tolerate if it significantly improves the quality of the end result (incidentally, this is why we tolerate it in the case of latent diffusion).
Self-distillation
As previously mentioned, a flow map parameterised by the average velocity contains within it a velocity predictor as a special case: \(V(\mathbf{x}_t, t, t) = v(\mathbf{x}_t, t)\). So if we ensure that we occasionally sample \(s = t\) during training, and combine the consistency-based loss function of our choice with the standard diffusion loss applied to those cases, we don’t need a pre-trained model that provides ‘ground truth’ for \(v(\mathbf{x}_t, t)\). By balancing both losses, the model will simultaneously learn both the instantaneous velocity as well as its integral over finite time step intervals. As an example, we can combine the Lagrangian consistency loss with the diffusion loss:
\[\mathcal{L}_\mathrm{flow\,map} = \overbrace{\mathbb{E}\left[ \left( V(\mathbf{x}_t, t, t) - (\mathbf{\varepsilon} - \mathbf{x}_0) \right)^2 \right]}^{\mathrm{diffusion\,loss}}\\+ \underbrace{ \mathbb{E} \left[ \left( V(\mathbf{x}_s, s, t) - V( F(\mathbf{x}_s, s, t), t, t) + (t - s) \dfrac{\partial}{\partial t} V(\mathbf{x}_s, s, t) \right)^2 \right] }_{\mathrm{Lagrangian\,consistency\,loss}} .\]Note that we have also substituted the appearance of \(v(\mathbf{x}_t, t)\) in the Lagrangian consistency loss term with \(V(\mathbf{x}_t, t, t)\) to enable from-scratch training.
We could also use this dual loss setup in combination with a pre-trained diffusion model, substituting \(\mathbf{\varepsilon} - \mathbf{x}_0\) with its velocity estimate to reduce the variance of the diffusion loss term, but this is not strictly necessary. Even if we don’t, it makes sense to interpret this as a form of self-distillation2: the model is simultaneously being trained as a teacher and being distilled into itself.
My own experience with neural network training setups where teacher training and student distillation are simultaneous rather than sequential, is that they can work pretty well in practice (my colleagues and I used this idea for representation learning at some point18). Results are usually as good or almost as good as having two sequential training stages (first the teacher, then the student), but without a lot of the hassle caused by the sequential dependency.
Marginal-from-conditional learning
Some flow map training formulations admit an alternative approach, which requires only a single consistency-based loss to train from scratch. To understand how this is possible, it is worth revisiting how diffusion training works: a denoiser learns to predict \(\mathbb{E}\left[\mathbf{x}_0 \mid \mathbf{x}_t\right]\), even though we supervise it with samples from \(p(\mathbf{x}_0, \mathbf{x}_t)\) during training. It is never directly supervised to predict the conditional expectation, but because it is forced to make a single prediction across all possible samples of \(p(\mathbf{x}_0, \mathbf{x}_t)\), it automatically lands on the expectation as the best way to minimise the overall error. This is sometimes known as the marginalisation trick, because it enables learning the marginal velocity from velocities conditioned on \(\mathbf{x}_0\)19.
How can we apply this same trick to flow map training? There are two different approaches to make this work, both starting from the Eulerian consistency rule: MeanFlow12 and improved MeanFlow 20 (iMF). Let’s look at the original MeanFlow approach first. Using the average velocity formulation, we have:
\[V(\mathbf{x}_s, s, t) = v(\mathbf{x}_s, s) + (t - s) \left( \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right) .\]If we treat the right hand side of this equality as the target for learning, and wrap it in a stop-gradient operation, we can substitute the marginal velocity \(v(\mathbf{x}_s, s)\) by the conditional velocity, which is simply \(\mathbf{\varepsilon} - \mathbf{x}_0\) (as in diffusion). This will leave the minimum of the MSE loss unchanged. It’s worth taking a moment to dissect exactly why we are allowed to do this. It hinges on four important features:
- We use the mean squared error as the loss.
- The velocity is evaluated at the current noisy input \(\mathbf{x}_s\).
- The prediction target is linear in the velocity \(v(\mathbf{x}_s, s)\).
- The stop-gradient operation ensures that the resulting update direction remains linear in the velocity.
Let’s call the residual \(R\): this is the difference between the left hand side and the right hand side of the consistency rule. \(R\) is linear in \(v(\mathbf{x}_s, s)\). The loss function we are minimising is then simply \(\mathbb{E}\left[R^2\right]\). If we take the gradient of this loss function with respect to our model parameters \(\theta\), we get:
\[G_\theta = \nabla_\theta \mathbb{E} \left[ R^2 \right] = \mathbb{E} \left[ 2R \nabla_\theta R \right] .\]But because the prediction target is wrapped in a stop-gradient operation, this is not actually the update direction we use. Instead, we end up with:
\[\widetilde{G}_\theta = \mathbb{E} \left[ 2R \nabla_\theta V \right] ,\]because \(V(\mathbf{x}_s, s, t)\) is the only part of \(R\) that sits outside the stop-gradient operation. Therefore, the update direction \(\widetilde{G}_\theta\) is also linear in the velocity. If we swap out \(v(\mathbf{x}_s, s)\) for \(\mathbf{\varepsilon} - \mathbf{x}_0\), the expectation operator ensures that we still get exactly the same result, because the expectation is conditional given \(\mathbf{x}_s\).
Note that this would not be the case if it weren’t for the stop-gradient operation: the ‘proper’ gradient \(G_\theta\) contains the product of \(R\) and \(\nabla_\theta R\), both of which depend on the velocity, so this update direction is not at all linear in the velocity, and the marginal-from-conditional learning trick would completely break down!
If the velocity were evaluated anywhere else than \(\mathbf{x}_s\), it also wouldn’t work: substituting the marginal velocity with the conditional velocity \(\mathbf{\varepsilon} - \mathbf{x}_0\) only works because we are calculating a conditional expectation given \(\mathbf{x}_s\). This is why we cannot give the Lagrangian consistency rule the same treatment: it requires evaluating the velocity at \(\mathbf{x}_t = F(\mathbf{x}_s, s, t)\). So even though the prediction target is also linear in the velocity, and we can use the stop-gradient operation to ensure that the update direction remains linear in the velocity, the expectation is conditioned on the wrong variable for the substitution to work.
It is fair to say that the stop-gradient operation in MeanFlow is doing double duty: it avoids higher-order differentiation (no backprop through derivatives), and it enables marginal-from-conditional learning. At a glance, it looks like a tweak to make training more efficient, but it is actually crucial for training to work at all.
For improved MeanFlow (iMF), we start from the same average velocity formulation of the Eulerian consistency rule, but with a twist: we make \(V(\mathbf{x}_s, s, t)\) and \(v(\mathbf{x}_s, s)\) swap sides:
\[v(\mathbf{x}_s, s) = V(\mathbf{x}_s, s, t) - (t - s) \left( \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right) .\]Now we have an expression for the instantaneous velocity \(v\) at the starting point \(s\) in terms of the average velocity \(V\) over the interval between \(s\) and \(t\). It is unfortunately self-referential, as the instantaneous velocity appears inside the Jacobian-vector product (JVP) on the right hand side. But recall that the instantaneous velocity is also just the average velocity over an empty interval: \(v(\mathbf{x}_s, s) = V(\mathbf{x}_s, s, s)\), so:
\[v(\mathbf{x}_s, s) = V(\mathbf{x}_s, s, t) - (t - s) \left( \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) V(\mathbf{x}_s, s, s) \right) .\]Now, we can interpret the expression the right side as simply a reparameterisation of a standard diffusion or flow matching model, and train it as if it is one. In other words, we define:
\[W(\mathbf{x}_s, s, t) = V(\mathbf{x}_s, s, t) - (t - s) \mathrm{sg} \left[ \dfrac{\partial}{\partial s} V(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} V(\mathbf{x}_s, s, t) V(\mathbf{x}_s, s, s) \right] .\](Confusingly the iMF paper uses the notation \(V\) for this, but I have already used that letter for the average velocity. Sorry!) Note the stop-gradient operation wrapping the calculation of the JVP. We can use \(W\) as the predictor in the usual MSE loss:
\[\mathcal{L}_\mathrm{iMF} = \mathbb{E} \left[ \left( W(\mathbf{x}_s, s, t) - (\mathbf{\varepsilon} - \mathbf{x}_0) \right)^2 \right] .\]Training the ‘diffusion model’ \(W\) now forces \(V\) to learn the average velocity across intervals, and therefore, a full flow map, purely through its parameterisation. How neat is that?
Technically, we don’t even need any stop-gradient trickery to make this work, although in practice, the JVP is still wrapped in a stop-gradient operation to avoid higher-order differentiation. Unlike in traditional MeanFlow, however, the stop-gradient is not at all necessary for the method to work correctly! Aside from being more elegant, the improved MeanFlow loss also tends to have much lower variance in practice.
Flow maps in practice

Now that we have established what flow maps are, how they relate to diffusion models and how to train them, let’s take a closer look at some concrete implementations described in the literature. As usual, this is an opinionated selection of papers, and I do not purport to give an exhaustive overview. Feel free to drop any glaring omissions (or just interesting related work) in the comments below. This is going to be relatively dry, so I won’t be offended if you skip ahead to the end of the section, where I will summarise everything in a table.
If you are planning to read any of the papers mentioned, it is worth being aware of some of the notational variations you might encounter:
- The direction of time can be from data (\(t=0\)) to noise (\(t=1\)), following the diffusion convention, or from noise (\(t=0\)) to data (\(t=1\)), following the flow matching convention. I have stuck with the former, but many papers use the latter instead.
- The source and target time steps are sometimes given in reverse order, specifying the target first, and then the source, i.e. \(F(\mathbf{x}_s, t, s)\) instead of \(F(\mathbf{x}_s, s, t)\). Sometimes the target time step is fixed, and therefore omitted (as in consistency models11): \(F(\mathbf{x}_t, t)\).
- The time steps can be arguments to a function (e.g. \(F(\mathbf{x}_s, s, t)\)), but they are often specified as indices instead (e.g. \(F_{s,t}(\mathbf{x}_s)\)). I prefer explicit function arguments, because we often need to take (partial) derivatives with respect to these time steps.
- Functions representing flow maps and diffusion models can use lower case letters, upper case letters or Greek letters. Time steps are often \(s\) and \(t\), \(t\) and \(s\) or \(t\) and \(r\), there is no standard convention. I like \(s\) for ‘source’ and \(t\) for ‘target’, so that’s what I’ve stuck with, but many papers actually use them the other way around!
There were several instances during the writing of this blog post where these discrepancies got me hopelessly confused. If you look out for them and spend some time to make sure you are interpreting the notation correctly, you might save yourself a lot of hassle. It is also important to keep in mind the choice of parameterisation (flow map \(F\), average velocity \(V\), or something else). As we have seen before when discussing the consistency rules, this choice can make the formulas look quite different.
Training a diffusion model is remarkably simple, when you think about it: you only need very basic concepts such as Gaussian noise and the the mean squared error loss. As we have already seen, training flow maps is quite a bit more involved by comparison. Often, it is also more costly, requiring multiple passes through the model to perform a single training step.
Lagrangian methods 🐱
Boffi et al. describe Lagrangian map distillation1 (LMD). Given a pre-trained teacher model that predicts the velocity, minimise:
\[\mathcal{L}_{\mathrm{LMD}} = \mathbb{E} \left[ \left( \frac{\partial}{\partial t} F(\mathbf{x}_s, s, t) - v(F(\mathbf{x}_s, s, t), t) \right)^2 \right] .\]They suggest using forward-mode differentiation (JVP with tangent vector \([0, 0, 1]\)) to efficiently calculate \(\frac{\partial}{\partial t} F(\mathbf{x}_s, s, t)\) and \(F(\mathbf{x}_s, s, t)\) simultaneously. Note the lack of stop-gradient operations, so minimising the loss function requires higher-order differentiation. Although the loss is expressed in terms of \(F\), they suggest predicting \(V\). For from-scratch training, a self-distillation variant can be constructed2 by replacing the velocity with the flow map’s own prediction (note the introduction of a stop-gradient operation), and combining it with a standard diffusion loss (see section 4.1):
\[\mathcal{L}_{\mathrm{LSD}} = \\ \mathbb{E} \left[ \left( \frac{\partial}{\partial t} F(\mathbf{x}_s, s, t) - \mathrm{sg} \left[ V(F(\mathbf{x}_s, s, t), t, t) \right] \right)^2 \right] + \mathbb{E}\left[ \left( V(\mathbf{x}_t, t, t) - (\mathbf{\varepsilon} - \mathbf{x}_0) \right)^2 \right] .\]Align Your Flow21 proposes a similar distillation approach (AYF-LMD), but arrives at it from a compositional perspective: taking a large step from \(s\) to \(t\) should be equivalent to taking slightly smaller step from \(s\) to \(t - \Delta t\), and then using the teacher model to go the rest of the way to \(t\) (i.e. a diffusion sampling step):
\[F(\mathbf{x}_s, s, t) = F(\mathbf{x}_s, s, t - \Delta t) + \Delta t \cdot v(F(\mathbf{x}_s, s, t - \Delta t), t - \Delta t) .\]They construct a loss from this identity, by wrapping the right-hand side in a stop-gradient operator and squaring the residual, and then taking the limit for \(\Delta t \rightarrow 0\). They show that this recovers \(\mathcal{L}_\mathrm{LMD}\) (except of course for the stop-gradient, which helps avoid higher-order differentiation). Although they note it is more stable than their Eulerian approach (see section 5.2) in toy experiments, they also point out that it fails to produce good results on real images.
Terminal Velocity Matching17 (TVM) follows a similar recipe, but targets training from scratch using self-distillation (see section 4.1). Their ‘terminal velocity condition’ is precisely the Lagrangian consistency rule, and the TVM loss consists of a Lagrangian consistency term and a flow matching (diffusion) term. Interestingly, they suggest using a stop-gradient operation on the weights for some of the model invocations, and even exponentially averaged (EMA) weights for one of them. However, they do not apply this operation to the derivative term that appears in the consistency loss term, so higher-order differentiation is required for training. They point out that this necessitates a custom FlashAttention kernel, which they have open-sourced, as well as several architecture and optimisation tweaks, such as a Lipschitz continuity constraint.
FreeFlow22 figures out a clever way to make flow map distillation entirely data-free, using Lagrangian consistency as a starting point. They exclusively draw samples from the noise distribution to successfully distill a diffusion model into a flow map. They also make a compelling argument for why you would want to eliminate the requirement of a training data distribution altogether: it might not actually be representative of the samples the diffusion model is able to generate, even if it was trained on that distribution itself! This can be because of interventions like classifier-free guidance, but also simply because the model has learnt to generalise beyond the data distribution. And sometimes, the original data distribution simply isn’t accessible at the time of distillation.
It is clearly suboptimal if the data distribution used to perform flow map distillation isn’t representative of the sampling trajectories we are trying to model. But how can you train a neural network without data? They achieve this feat by combining two ingredients:
- A Lagrangian consistency distillation loss, using the average velocity formulation, with the source time step anchored to \(s = 1\). They always start from pure noise \(\mathbf{\varepsilon} \sim \mathcal{N}(0, 1)\) and minimise (using a finite-difference approximation for the derivative):
- An auxiliary denoiser model is concurrently trained on one-step flow map samples, \(F(\mathbf{\varepsilon}, 1, 0)\), by renoising them according to the original corruption process. They then compare the velocity predicted by this denoiser to the teacher velocity, and use the discrepancy between the two to update the flow map. This helps to ground the distribution \(p(\mathbf{x}_0)\) implied by the flow map.
They show that each component in isolation is not sufficient to learn a good flow map model: using only the auxiliary denoiser is prone to collapse, and using only the Lagrangian consistency loss is prone to error accumulation. FreeFlow is closely related to BOOT23, an earlier data-free distillation method based on Lagrangian consistency, which I have previously discussed on this blog.
Physics Informed Distillation24 (PID) draws inspiration from physics-informed neural networks (PINNs), where people have been using neural networks to learn the solution operator of differential equations for a long time. Those methods are just as applicable to the ODE used for deterministic sampling from diffusion models, as they are to ODEs that describe physical phenomena. This yields another data-free distillation variant based on Lagrangian consistency. Like in FreeFlow, the derivative is handled by using a finite-difference approximation, but here, the stop-gradient operation only wraps the teacher velocity:
\[\mathcal{L}_\mathrm{PID} = \mathbb{E} \left[ \left( V(\mathbf{\varepsilon}, 1, t) - \mathrm{sg} \left[ v( F(\varepsilon, 1, t), t) \right] + (t - 1) \dfrac{\partial}{\partial t} V(\varepsilon, 1, t) \right)^2 \right] .\]They mention that avoiding backpropagation through the teacher is essential, because it enables the student to exploit weaknesses in the teacher (a similar phenomenon to adversarial examples).
Eulerian methods 🐔
Eulerian map distillation1 (EMD) uses a loss that is straightforwardly derived from Eulerian consistency (using velocity estimates from a pre-trained teacher model):
\[\mathcal{L}_{\mathrm{EMD}} = \mathbb{E} \left[ \left( \dfrac{\partial}{\partial s} F(\mathbf{x}_s, s, t) + \nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t) v(\mathbf{x}_s, s) \right)^2 \right].\]As with LMD, a self-distillation version can be constructed2 by replacing the velocity with the flow map’s own prediction, and combining it with a standard diffusion loss. A stop-gradient operation is added to wrap the spatial part of the Jacobian \(\nabla_{\mathbf{x}_s} F(\mathbf{x}_s, s, t)\).
Align Your Flow21 also features an Eulerian distillation method (AYF-EMD). As with the Lagrangian version, they start by comparing a large step and a slightly smaller one:
\[F(\mathbf{x}_s, s, t) = F(\mathbf{x}_{s + \Delta s}, s + \Delta s, t) ,\]where \(\mathbf{x}_{s + \Delta s} = \mathbf{x}_s + \Delta s \cdot v(\mathbf{x}_s, s)\). The right-hand side is wrapped in a stop-gradient operation, and the squared residual is used as the loss. They show that letting \(\Delta s \rightarrow 0\) recovers \(\mathcal{L}_\mathrm{EMD}\), once again excepting the stop-gradient operation, which in this case helps avoid backpropagation through the spatial part of the Jacobian. For their best results, they combine this with autoguidance25 applied to the teacher, a warmup training phase with linearity regularisation, and an adversarial finetuning phase where the EMD loss is combined with an adversarial loss.
Solution Flow Models26 (SoFlow) follow a very similar recipe, with two key differences:
- They focus on learning flow maps from scratch, and use self-distillation as the mechanism to do so (whereas AYF is focused on distillation from a pre-trained diffusion model);
- The Jacobian-vector product is avoided through a finite-difference approximation (\(\Delta s\) is small but finite, rather than infinitesimal), with one side of it wrapped in a stop-gradient operation.
To make the finite difference approximation work well in practice, they tweak the loss weighting and use a curriculum to gradually decrease \(\Delta s\) over the course of training.
Flow-anchored consistency models27 (FACM) are also similar to AYF in spirit, but use an interesting trick to improve training stability, which they call ‘flow anchoring’. The base version of FACM considers \(t=0\) only: the target time step is fixed, as in consistency models. They then extend the range of the source time step \(s\) from \([0, 1]\) to \([0, 2]\). When \(s > 1\), the model is expected to operate as a denoiser. This results in a single model with a flow map mode and a denoiser mode, which shares parameters across these two tasks. This is said to ‘anchor’ the parameters of the model: the auxiliary denoiser task acts as a regulariser for flow map learning.
The flow anchoring parameterisation is combined with an efficient JVP implementation. They also consider a version where \(t\) is allowed to vary, enabling full flow map learning. Interestingly, in that setting, the model learns a denoiser twice: once for the auxiliary denoiser task (\(s > 1\)), and once for the flow map task when \(t = s\). Despite the apparent redundancy, the auxiliary task still seems to be helpful even in this case.
Unlike the preceding approaches, MeanFlow12 (MF) does not rely on (self-)distillation, but on marginal-from-conditional learning, just like standard diffusion or flow matching models. The mechanics of this were already explained in a previous section (including the improved MeanFlow20 variant). The practical implementation of MF involves adaptive weighting to avoid volatility as \(s\) and \(t\) get close to each other. In addition, the \(s = t\) case is significantly oversampled during training to keep the model grounded.
Many variants and extensions of MeanFlow have been explored. Here are a few:
-
AlphaFlow28 suggests a curriculum learning approach, smoothly interpolating from learning the instantaneous velocity (flow matching) to the average velocity (MF) over the course of training.
-
Decoupled MeanFlow29 (DMF) proposes an architectural tweak: condition the earlier layers of the network only on the source time step \(s\), and the later layers only on the target time step \(t\). This makes it quite straightforward to adapt a pre-trained denoiser into a MeanFlow model: simply decouple the time embeddings for the earlier and later layers, and then fine-tune. They also suggest using a Cauchy variant of the MF loss to supress outliers.
-
Rectified MeanFlow30 starts from the following observation: if all paths between data and noise are completely straight, the instantaneous velocity and average velocity (over any interval) coincide everywhere! The less curved the paths, the easier it will be to adapt a denoiser into a MeanFlow model. They suggest combining a single reflow10 stage with MF training.
-
Pixel MeanFlow31 (pMF) notes that the computational benefits of generative modelling in latent space start to wane when your model needs very few steps to produce good samples. At that point, the relative simplicity of operating directly in input space might be preferable, so they explore how to adapt iMF for this setting.
Compositional methods 🐶
Shortcut models32 use a loss function in terms of the average velocity \(V\) based on the compositional consistency rule, grounded with self-distillation:
\[\mathcal{L}_\mathrm{shortcut} = \mathbb{E}\left[ \left( V(\mathbf{x}_s, s, s + 2h) - \mathrm{sg} \left[ \hat{V}_\mathrm{s + 2h} \right] \right)^2 \right] + \mathbb{E}\left[ \left( V(\mathbf{x}_t, t, t) - (\mathbf{\varepsilon} - \mathbf{x}_0) \right)^2 \right] ,\]where \(\hat{V}_\mathrm{s + 2h} = \frac{V(\mathbf{x}_s, s, s + h) + V(\hat{\mathbf{x}}_{s + h}, s + h, s + 2h)}{2}\) and \(\hat{\mathbf{x}}_{s + h} = \mathbf{x}_s + h V(\mathbf{x}_s, s, s + h)\). This looks a bit gnarly at first, but it is simply saying that the average velocity over a time interval of length \(2h\) should be the mean of the average velocities over two intermediate time intervals with length \(h\). This strategy of bootstrapping by doubling the step size is very similar to progressive distillation33. Note that no derivatives feature anywhere in the loss.
SplitMeanFlow34, which might sound like it belongs in the previous section, is actually a generalisation of shortcut models, where the time intervals that are composed are not restricted to be the same length. They focus on distillation instead of from-scratch training. Boffi et al. recover the self-distillation variant as Progressive self-distillation2 (PSD).
Flow Map Matching1 (FMM) takes a slightly different approach: recall that compositionality implies that a flow map is its own inverse, \(F(F(\mathbf{x}_s, s, t), t, s) = \mathbf{x}_s\). Taking the partial derivative w.r.t. \(s\), we also get:
\[\frac{\partial}{\partial s}F(F(\mathbf{x}_s, s, t), t, s) = v(\mathbf{x}_s, s) .\]Combined, these two equalities are used to construct the FMM loss:
\[\mathcal{L}_\mathrm{FMM} = \mathbb{E} \left[ \left( \frac{\partial}{\partial s} F(F(\mathbf{x}_s, s, t), t, s) - (\mathbf{\varepsilon} - \mathbf{x}_0) \right)^2 \right] + \mathbb{E} \left[ \left( F(F(\mathbf{x}_s, s, t), t, s) - \mathbf{x}_s \right)^2 \right].\]Note the use of marginal-from-conditional learning for the first term, which enables from-scratch flow map training. Unfortunately, this term also reintroduces a time derivative, but since it is a partial derivative w.r.t. \(s\), it does not require backpropagation into \(F(\mathbf{x}_s, s, t)\). They find that this method works best when the time interval \(\mid t - s \mid\) is restricted so it is not too large, which means it is not suitable for learning to sample in one step.
To address the latter, they also suggest Progressive Flow Map Matching (PFMM):
\[\mathcal{L}_\mathrm{PFMM} = \mathbb{E} \left[ \left( F(\mathbf{x}_s, s, u) - F_\mathrm{pre}(F_\mathrm{pre}(\mathbf{x}_s, s, t), t, u) \right)^2 \right] ,\]where \(F_\mathrm{pre}\) represents a pre-trained flow map across a limited time interval. This is arguably the purest application of the compositional consistency rule, but it does require a pre-existing partial flow map to work (which can be obtained through FMM or another method).
What about consistency models?
There is a long line of work around consistency models dating back to 2023. I wrote about some of it in a previous blog post. The original Consistency Models paper11 (CM) set off something of a chain reaction, as people came to realise that predicting velocities is only one of many ways to characterise paths between noise and data. Although the ‘flow map’ framing did not come until much later, I have chosen to use it for this blog post, because I think it provides a helpful framework for understanding how all of this work relates to each other. Many recent works have also adopted it.
That said, it is worth taking a moment to see how some of these original works fit into the modern framework. Consistency Distillation (CD) produces a flow map with the target time step anchored to \(t=0\) (data side):
\[\mathcal{L}_\mathrm{CD} = \mathbb{E} \left[ \left( F(\mathbf{x}_s, s, 0) - \mathrm{sg} \left[ F(\hat{\mathbf{x}}_{s - \Delta s}, s - \Delta s, 0) \right] \right)^2 \right] ,\]with \(\hat{\mathbf{x}}_{s - \Delta s} = \mathbf{x}_s - \Delta s \cdot v(\mathbf{x}_s, s)\), the output of a single Euler sampling step over the time interval \(\Delta s\). In this way, the loss quite literally propagates predictions from small time steps (closer to data) to large time steps (closer to noise). Taking the limit as \(\Delta s \rightarrow 0\) recovers Eulerian map distillation. Consistency Training (CT) enables from-scratch learning by replacing the velocity \(v(\mathbf{x}_s, s)\) with the conditional velocity, but unlike MeanFlow, this now results in a biased estimate. They show the bias goes away as \(\Delta s \rightarrow 0\).
CD and CT construct a partial flow map (for \(t=0\) only), so sampling from consistency models in multiple steps involves reinjecting noise, because every step fully denoises the input. Several follow-up works improved upon the original training recipe, including improved consistency training35 (iCT), easy consistency tuning36 (ECT) and continuous-time consistency models37 (sCM), but they did not fundamentally alter the core learning mechanic. Consistency Trajectory Models38 (CTM) suggested to generalise this approach to \(t > 0\), resulting in a two-time flow map. I believe this was the first paper to do so (please correct me if I’m wrong). To make this work in practice, the loss is always calculated at \(t=0\) (i.e. in the input space) using an additional invocation of the flow map (with stop-gradient on the model parameters) \(F_\mathrm{sg}\):
\[\mathcal{L}_\mathrm{CTM} = \mathbb{E} \left[ \left( F_\mathrm{sg}(F(\mathbf{x}_s, s, t), t, 0) - \mathrm{sg} \left[ F(F(\hat{\mathbf{x}}_{s - \Delta s}, s - \Delta s, t), t, 0) \right] \right)^2 \right] .\]They also consider larger jumps for \(\Delta s\), which means multiple sampling steps are required to accurately construct \(\hat{\mathbf{x}}_{s - \Delta s}\).
Guidance
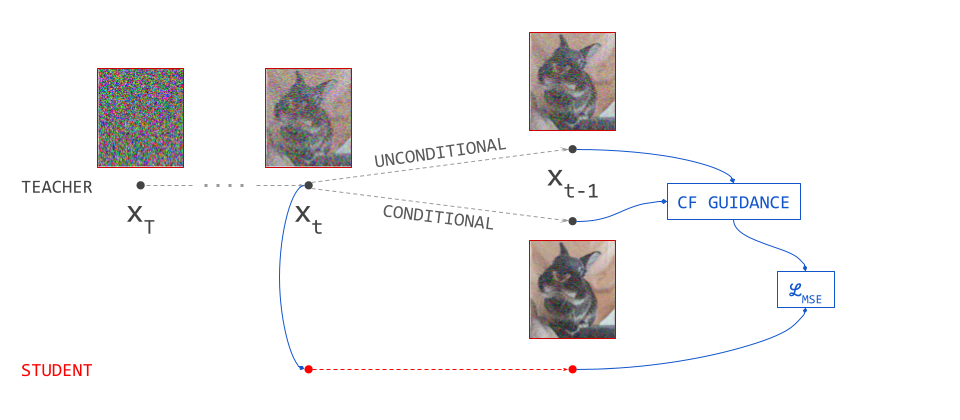
I won’t repeat here how classifier-free guidance (CFG) works, as I have already written two blog posts about it, but modern diffusion sampling almost always relies heavily on this trick. Naturally, we might also want to use guidance with flow maps, but this is actually not straightforward.
Applying guidance during diffusion sampling involves modifying the denoiser prediction at each step using relatively simple linear operations. Because the modified prediction gets fed back into the denoiser model at the next step, the changes compound to have a highly complex and non-linear effect on the output of the sampling procedure. That makes this technique very powerful, despite its relative simplicity. It comes into conflict with distillation however, whose point is to dramatically reduce the number of sampling steps, which also reduces this compounding effect.
The easiest way to address this is to avoid applying guidance to the distilled model itself, and instead, apply it to the teacher model during distillation39. The effect will then be incorporated and emulated by the student. This can be done in a few different ways: the simplest is to tune the guidance scale for the teacher and fix it during distillation, after which it cannot be changed. Instead of classifier-free guidance, other variants like autoguidance25 can also be used in this way (as in e.g. AYF21).
A more advanced approach is to randomise the guidance scale, and feed the selected value into the student network as an extra conditioning signal (as in e.g. improved MeanFlow20 and Terminal Velocity Matching17). The network then has to learn to incorporate the effect of guidance directly. This can be done both for distillation and for from-scratch training, using guidance-free training40 (GFT).
Aside from helping to produce higher-quality samples, guidance also greatly simplifies the distribution that needs to be captured by the flow map. This is welcome, because flow maps are significantly more complex objects to model compared to denoisers. Simpler distributions are easier to model accurately with few steps.
Tricks of the trade
Flow map training dynamics can be quite chaotic due to the self-referential nature of consistency-based loss functions, but there are many other potential sources of instability as well, such as guidance-free training. All of the concrete implementations we have discussed come with a bag of tricks to reduce variance and help stabilise training. Exploring them all in detail would take us too far, but I would like to point out some general patterns:
-
Initialisation: most approaches initialise the weights of the flow map model using the weights of a denoiser. In a distillation setting, this can be a copy of the teacher weights. An alternative approach is consistency mid-training41 (CMT), which is supposed to help bridge the gap between predicting infinitesimal steps (as a denoiser does) and larger finite steps.
-
Output parameterisation: we have already discussed in section 1.3 that flow maps can be parameterised to predict the target position on the path (\(F\)), or the average velocity between the source and target position (\(V\)). Both of these can actually be challenging prediction targets for neural networks, as they are partially noisy. For diffusion models, it was recently suggested that parameterising the neural network to predict \(\hat{\mathbf{x}}_0\) is advantageous42, because data tends to live on a lower-dimensional nonlinear manifold within the high-dimensional output space, whereas isotropic noise (and therefore, noisy data) does not. Pixel MeanFlow31 extends this idea to flow maps, by parameterising the network to predict the ‘denoised image field’, which is a simple linear function of the average velocity and the current noisy input that is noise-free.
-
Time step conditioning: unlike denoisers, which are conditioned on one time step, flow maps are conditioned on both a source and a target time step (except for some partial flow map variants, like consistency models). The simplest way to handle this is to have separate time step embeddings for both in the network. As an alternative, Decoupled MeanFlow29 suggests partitioning the layers of the model, conditioning the earlier layers only on the source time step, and later layers only on the target time step. Yet another option is to condition the model on the difference between the time steps, i.e. the length of the interval. This is analogous to training a denoiser without any time step conditioning at all, which can work remarkably well in practice8 9.
-
Time step sampling and loss weighting: as with diffusion models, tweaking the time step sampling strategy during training is of paramount importance to ensure the model focuses its capacity on learning the right things. Since there are now two time steps to sample for each training example, these strategies can get quite complicated. Time-step dependent loss weighting is also very common, to account for the increased prediction difficulty as the time steps get farther apart, and to combat variance and balance gradient magnitudes. This is not surprising, given that training a flow map is essentially a massive multi-task learning problem. Since information propagates from small time step intervals to large ones, the \(s=t\) case is often significantly oversampled. When guidance is in play, guidance-dependent scaling is also common.
-
Loss functions: sometimes, robust loss functions are used to reduce the impact of outliers (e.g. pseudo-Huber loss used in iCT35), and perceptual loss functions are used to improve sample quality (e.g. LPIPS43 used in CM11, CTM38 and PID24).
-
Curricula: since flow map training often boils down to fine-tuning a denoiser model in practice, various strategies have been developed to make this change in tasks less abrupt, and to help the model bootstrap its long-range predictions from shorter-range ones. This is can be implemented by gradually increasing the maximal distance between \(s\) and \(t\) over the course of training, for example. It is also common to train partial flow maps, which do not support making predictions for all possible pairs of \(s\) and \(t\) (e.g. FMM1).
The landscape
To wrap up this section, here is a tabular overview of the methods we have discussed:
- The consistency rule on which each method is based is indicated by 🐶 (compositional), 🐱 (Lagrangian) or 🐔 (Eulerian).
- The learning setting is indicated by 🧑🏫 (distillation), 🪃 (from scratch, self-distillation) or 🌊 (from scratch, marginal-from-conditional learning).
- The output parameterisation is indicated by 🎯 (\(F\), target position on the path) or 🚀 (\(V\), average velocity). Note that sometimes, the loss is expressed in terms of \(F\) even when the network is parameterised to predict \(V\).
- JVP = Jacobian-vector product, SG = stop-gradient operation, FD = finite-difference approximation, aux = auxiliary denoiser.
| Method | Notes | Cost |
|---|---|---|
| Lagrangian Map Distillation1 (LMD) | 🐱🧑🏫🚀 JVP, no SG | 9 |
| Lagrangian Self-distillation2 (LSD) | 🐱🪃🚀 SG on target | 10 |
| Align Your Flow21 (AYF-LMD) | 🐱🧑🏫🚀 SG on JVP | 6 |
| Terminal Velocity Matching17 (TVM) | 🐱🪃🚀 SG on target | 10 |
| FreeFlow22 | 🐱🧑🏫🚀 \(s=1\) only, SG on FD + aux | 12 |
| Physics Informed Distillation24 (PID) | 🐱🧑🏫🎯 \(s=1\) only, FD, SG on target | 7 |
| Consistency Training11 (CT) | 🐔🪃🎯 \(t=0\) only | 4 |
| Consistency Distillation11 (CD) | 🐔🧑🏫🎯 \(t=0\) only | 5 |
| Consistency Trajectory Models38 (CTM) | 🐔🧑🏫🎯 loss evaluation at \(t=0\) | 7 |
| Eulerian Map Distillation1 (EMD) | 🐔🧑🏫🚀 JVP, no SG | 7 |
| Eulerian Self-distillation2 (ESD) | 🐔🪃🚀 SG on spatial JVP | 10 |
| Align Your Flow21 (AYF-EMD) | 🐔🧑🏫🚀 SG on JVP | 6 |
| SoFlow26 | 🐔🪃🚀 SG on FD | 7 |
| Flow-anchored Consistency Models27 (FACM) | 🐔🧑🏫🚀 SG on JVP | 8 |
| MeanFlow12 (MF) | 🐔🌊🚀 SG on target | 4 |
| Improved MeanFlow20 (iMF) | 🐔🌊🚀 SG on target | 5 |
| Shortcut Models32 | 🐶🪃🚀 SG on target | 8 |
| SplitMeanFlow34 | 🐶🧑🏫🚀 SG on target | 9 |
| Progressive Self-distillation2 (PSD) | 🐶🪃🚀 SG on target | 8 |
| Flow Map Matching1 (FMM) | 🐶🌊🚀 JVP, no SG | 9 |
| Progressive Flow Map Matching1 (PFMM) | 🐶🧑🏫🚀 Flow map teacher | 5 |
An estimate of the cost of a single training iteration is also included in the table, using the ‘forward pass equivalent’ (FPE) metric. This assumes that a backward pass costs roughly twice as much as a forward pass (so run-of-the-mill neural network training has a cost of 3 FPE). We also assume that calculating a JVP and forward pass jointly costs twice as much as the forward pass alone, and calculating a backward pass through this combined operation costs 4 times as much. Needless to say, this is a rough approximation: in practice, some of these costs can be lower due to dead code elimination and other compiler optimisations, but also higher due to e.g. rematerialisation.
I have not included any additional costs caused by guidance (usually teacher guidance adds one extra FPE). Most methods with loss functions with multiple terms suggest using sub-batches for the different terms, and calculating the cheap terms more often, which can greatly reduce the effective cost in terms of FPE. For a fair comparison, I have not taken this into account, and assume that the full loss is calculated on the entire training batch.
It is incredibly easy to make mistakes when calculating these numbers, so I apologise for any inaccuracies (please feel free to point them out). Whether the computation graph is compiled (as with JAX or torch.compile) or not can also matter in practice. I have assumed that this is the case.
Applications and extensions

The obvious application of flow maps is faster sampling, but they have some other cool tricks up their sleeve. They can also be extended in interesting ways.
Faster sampling at scale
Terminal velocity matching17 has been applied to an image generation model with more than 10 billion parameters – all the more impressive, considering that it requires backpropagation through the JVP in the loss. Flow-anchored consistency models27 were used to distill the 14B parameter Wan 2.2 video generation model on an image dataset, producing samples in 2-8 steps. Align Your Flow was used to distill the FLUX.1-dev image generation model and produce samples in 4 steps.

A slightly older success story is LCM-LoRA44: low-rank adaptation (LoRA) modules for various variants of Stable Diffusion45, which turn it from a diffusion model into a consistency model, enabling few-step sampling. Surprisingly, these modules are also able to work their magic on various fine-tuned versions of the original Stable Diffusion checkpoints, without modification.
In the audio domain, notable applications include ByteDance’s use of SplitMeanFlow34 for their speech synthesis products, and Continuous Audio Language Models46 (CALM), which have been applied to speech and music generation (samples of both are available here).
Efficient steering and post-training
Diffusion sampling is very malleable, with tweaks such as guidance proving highly effective in many applications. People have wanted to steer diffusion sampling based on arbitrary reward signals, but this is actually not straightforward: these signals are usually defined in terms of clean data, but during sampling, we only have noisy intermediate states. So by default, we can only really estimate rewards at the end of sampling. Unfortunately, by then, there is no more possibility for steering, so that defeats the point.
Reward-based steering requires an efficient way to look ahead at where the sample will end up. It should be differentiable, so that we can backpropagate reward signal gradients and use them to steer sampling. Several strategies have been explored for this:
- In some cases, the reward signal can be adapted so it is robust to noise, e.g. by training a classifier with noise augmentation to use for classifier guidance;
- Single-step diffusion sampling can be used, i.e. directly predicting \(\hat{\mathbf{x}}_0\) from the current noisy state \(\mathbf{x}_t\) in one pass47 48. This is sometimes referred to as Tweedie’s formula. It is a fast and differentiable way to do look-ahead, but it produces blurry results. Most off-the-shelf models used to calculate reward signals are more robust to blurry inputs than to Gaussian noise, so this can still be a significant improvement.
- Sequential Monte Carlo49 (SMC) involves drawing many samples in parallel. At each time step, trajectories with low reward scores (which can be evaluated using single-step diffusion sampling, for example) are removed, and trajectories with high scores are duplicated to replace them. This does not require backpropagating reward gradients, but it is quite expensive.
Flow maps offer an efficient differentiable look-ahead mechanism: instead of the blurry samples produced by single-step diffusion sampling, we can use ‘clean’ flow map samples to calculate the reward signal. Even if single-step sampling with flow maps is far from perfect, it will produce results that are much more in-distribution and less blurry than single-step diffusion sampling. Sabour et al. called this flow map trajectory tilting50 (FMTT). Xu et al. also explored this idea for inverse problems51, and Woo et al. used it for protein design52.
Once we have a flow map that enables fast sampling, we could also just use it to draw many samples in parallel and filter them (SMC-style, but without look-ahead). This works remarkably well for some types of rewards, but for others, gradient-based steering provides superior results50.
Although flow maps produce clean samples, they inevitably result in biased reward estimates when used for look-ahead. This is because an entire distribution of possible outcomes of the sampling process is represented by a single sample. It is not possible to draw multiple samples and average the reward across them, because flow maps are deterministic by design. Two workarounds have been explored for this:
- Variational Flow Maps53 (VFM) use a ‘noise adapter’ trained based on a reward signal, to constrain the initial noise distribution used to sample from the flow map.
- Meta Flow Maps54 and Diamond Maps55 are stochastic flow maps, which are able to model the full posterior distribution from a given noisy intermediate state, while still enabling differentiable one-step sampling.
Aside from improved steering at inference time, these tweaks also enable reward-based post-training use cases, where being able to explore the reward landscape without mode collapse is important.
Discrete data
Some three years ago, I wrote about diffusion language models on this blog, pointing out that there are two main strategies to apply diffusion to categorical data: using a discrete corruption process (e.g. masking), or embedding discrete data in a continuous space, and using continuous diffusion instead. The emphasis in the research community has been on the former for the past few years, but recently, the latter approach is making a comeback.
Flow maps are playing a key role in this: as diffusion language models are gaining traction, people have been studying distillation methods extensively. It turns out that distilling discrete diffusion models down to very few steps hits a roadblock: independence assumptions between tokens in the sequence are unavoidable, and significantly deteriorate sample quality. Continuous methods do not have this issue, so there has been renewed interest as they are seen as more ‘distillable’.
In the first half of 2026, several works about training flow maps for categorical data have appeared on arXiv, including Categorical Flow Maps56, Flow Map Language Models57 and Discrete Flow Maps58. All three demonstrate how to parameterise the flow map so that predictions are always constrained to the output space. This enables the use of the cross-entropy loss instead of the mean squared error for flow map training, which brings significant stability improvements. (This is the same idea as the ‘denoised image field’ parameterisation from pixel MeanFlow31, but applied here for a very different purpose.) Floor Eijkelboom recently published a really nice blog post about this revitalisation of continuous language diffusion research, which I had previously declared extinct after 2023.
On a personal note, I am quite excited about this, as my first and only diffusion paper to date was about Continuous Diffusion for Categorical Data59 (CDCD). The motivation for that work was precisely to address some apparent shortcomings of discrete diffusion (like its inability to represent superpositions of possible outcomes in intermediate noisy states), and to tap into the rich existing toolbox for continous diffusion (guidance, efficient sampling, distillation), while sticking with familiar language modelling staples like Transformers and cross-entropy training. It is quite satisfying to see some of these advantages start to materialise!
Along with Categorical Flow Maps and Flow Map Language Models, we now have three separate papers heralding the triumphant return of continuous methods for language diffusion😶🌫️
— Sander Dieleman (@sedielem) April 26, 2026
Can you tell I'm excited?🫨https://t.co/SKS4OFtSG8https://t.co/kJ3cuFsggdhttps://t.co/aXXU4bUSMT https://t.co/oSCZkQ8rrH
Other extensions
Aside from discrete data, extensions to other non-Euclidean spaces (Riemannian manifolds) have been explored60 52. This work is particularly relevant for scientific applications, where symmetries and curvature are commonly encountered. Another useful application is fast likelihood evaluation: diffusion models can be used to estimate likelihoods5, but the procedure is just as costly as sampling. The same flow map mechanism that speeds up sampling can be used to speed up this procedure as well61 62.
Alternative strategies

Flow maps represent the trajectory-based approach to distilling diffusion models. For many applications, preserving the precise paths between noise and data is actually superfluous: the only thing we ultimately care about is to preserve the distribution at the data side, \(p(\mathbf{x}_0)\). Distributional distillation methods lean into this by relaxing the trajectory-preserving constraint. They minimise the distance between the generated distribution and the target distribution using score-based methods (Distribution Matching Distillation63, Score Identity Distillation64), statistical moments (Moment Matching Distillation65, Inductive Moment Matching66), adversaries (Adversarial Diffusion Distillation67, Continuous Adversarial Flow Models68), or the model’s own density estimates (Self-E69).
Not having to preserve precise trajectories gives the student model more freedom to achieve its goal, which often produces very high-quality results in the few-step regime. This comes at the cost of giving up the smooth topology of the bijection between noise and data, the ability to estimate likelihoods, and the ability to map inputs from data to noise, which is useful for image editing and interpolation.
Some methods don’t fit neatly in either category: a middle ground option is to use Reflow10 to straighten the paths, instead of giving up on the bijection completely. We also previously discussed FreeFlow22, which combines a trajectory-based Lagrangian consistency approach with a distributional auxiliary denoiser strategy.
A very recent addition in the distributional camp is FD-loss70, which suggests directly fine-tuning flow maps and diffusion models with a Fréchet distance metric as the loss function. Metrics like Fréchet Inception Distance (FID)71 have been used for evaluation of generative models for a long time, in spite of their perceived shortcomings. Using them as loss functions is difficult, because they require very large batch sizes. They work around that by backpropagating only through a smaller sub-batch (similar to BatchRenorm72). I think the most surprising result is that this can be applied directly to standard diffusion models to turn them into great one-step generators.

Pi-flow73 suggests another strategy to speed up diffusion sampling: rather than learning to integrate the ODE or using a distributional approach, sampling steps are decoupled from denoiser evaluations. Rather than predicting a velocity, the network predicts a ‘network-free’ policy (e.g. a Gaussian mixture model), which can be used to predict velocities cheaply. This enables sampling with many steps but very few network evaluations.
Drifting models74 mustered quite a bit of excitement recently, with a strategy for training one-step models that is conceptually related to diffusion, but quite different from it in practice: the distribution modelled by a feed-forward generator is evolved over the course of training using a ‘drifting field’ that pulls samples towards the data distribution. Personally, I am somewhat skeptical about the scalability of this approach, because it relies heavily on a good pre-trained feature space to work at all. Ivan Skorokhodov posted a great take about this work on Twitter.
Closing thoughts

First of all, thanks for sticking with me (and the animals 🐶🐔🐱) to the end! I hope this post provided a useful framework for recognising and understanding the relationships between various flow map methods, the consistency rules they are based on, and the tools at our disposal to make them practical and efficient. I hope I’ve also given you an idea of the possibilities they unlock.
Flow maps are not a silver bullet: their reliance on bootstrapping from denoisers (whether explicit, as in distillation, or implicit) already suggests that they get less reliable as the time interval we jump across increases. We are still calculating integrals after all – we are just precomputing them at training time (in an amortised way), instead of during sampling!
That said, with mature methods like improved MeanFlow (iMF) and Terminal Velocity Matching (TVM), promising applications to non-Euclidean and discrete data, and recent improvements to reward-based steering and fine-tuning, it certainly feels like we have come a long way towards making flow maps practically useful. What’s your flow map training recipe of choice? Please share your thoughts in the comments!
Disclosure regarding the use of AI in producing this blog post: I want to write in my own voice, and I want to respect everyone who takes the time to read what I write. Therefore, you will not find any passages or sentences in this post that are fully AI-generated. (Even the em dashes are all mine!) That said, I do occasionally consult AI when considering a particular turn of phrase, or to help me find the best wording (like a souped-up version of thesaurus.com). I primarily use it to help me understand papers and the relationship between them, and sometimes to create images and diagrams. AI was extensively used in the making of this blog post, but the prose is entirely ‘artisanal intelligence’. That is the level of AI involvement I am currently comfortable with.
If you would like to cite this post in an academic context, you can use this BibTeX snippet:
@misc{dieleman2026flowmaps,
author = {Dieleman, Sander},
title = {Learning the integral of a diffusion model},
url = {https://sander.ai/2026/05/06/flow-maps.html},
year = {2026}
}
Acknowledgements
Thanks to Bundle the bunny for modelling, and to kipply for permission to use this photograph. Thanks to my colleagues at Google DeepMind and to various members of the research community, whom I have discussed these topics with over the past year. Thanks especially to James Thornton, Valentin De Bortoli, Nicholas Boffi, Michael Albergo, Karsten Kreis and Xin Yu.
References
-
Boffi, Albergo, Vanden-Eijnden, “Flow map matching with stochastic interpolants: A mathematical framework for consistency models”, Transactions on Machine Learning Research, 2025. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10 ↩11
-
Boffi, Albergo, Vanden-Eijnden, “How to build a consistency model: Learning flow maps via self-distillation”, Neural Information Processing Systems, 2025. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9 ↩10
-
Lai, Song, Kim, Mitsufuji, Ermon, “The Principles of Diffusion Models”, arXiv, 2025. ↩
-
Ho, Jain and Abbeel, “Denoising Diffusion Probabilistic Models”, Neural Information Processing Systems, 2020. ↩
-
Song, Sohl-Dickstein, Kingma, Kumar, Ermon and Poole, “Score-Based Generative Modeling through Stochastic Differential Equations”, International Conference on Learning Representations, 2021. ↩ ↩2 ↩3
-
Song, Meng, Ermon, “Denoising Diffusion Implicit Models”, International Conference on Learning Representations, 2021. ↩
-
Lipman, Chen, Ben-Hamu, Nickel, Le, “Flow Matching for Generative Modeling”, International Conference on Learning Representations, 2023. ↩ ↩2
-
Sahraee-Ardakan, Delbracio, Milanfar, “The Geometry of Noise: Why Diffusion Models Don’t Need Noise Conditioning”, arXiv, 2026. ↩ ↩2
-
Kadkhodaie, Pooladian, Chewi, Simoncelli, “Blind denoising diffusion models and the blessings of dimensionality”, arXiv, 2026. ↩ ↩2
-
Liu, Gong, Liu, “Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow”, International Conference on Learning Representations, 2023. ↩ ↩2 ↩3
-
Song, Dhariwal, Chen, Sutskever, “Consistency Models”, International Conference on Machine Learning, 2023. ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Geng, Deng, Bai, Kolter, He, “Mean Flows for One-step Generative Modeling”, Neural Information Processing Systems, 2025. ↩ ↩2 ↩3 ↩4 ↩5
-
Grill, Strub, Altché, Tallec, Richemond, Buchatskaya, Doersch, Pires, Guo, Azar, Piot, Kavukcuoglu, Munos, Valko, “Bootstrap your own latent: A new approach to self-supervised Learning”, Neural Information Processing Systems, 2020. ↩
-
Caron, Touvron, Misra, Jégou, Mairal, Bojanowski, Joulin, “Emerging Properties in Self-Supervised Vision Transformers”, International Conference on Computer Vision, 2021. ↩
-
Salimans, Ho, “Should EBMs model the energy or the score?”, International Conference on Learning Representations, EBM Workshop, 2021. ↩
-
Dao, Fu, Ermon, Rudra, Ré, “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”, Neural Information Processing Systems, 2022. ↩
-
Zhou, Parger, Haque, Song, “Terminal Velocity Matching”, arXiv, 2025. ↩ ↩2 ↩3 ↩4 ↩5
-
De Fauw, Dieleman, Simonyan, “Hierarchical Autoregressive Image Models with Auxiliary Decoders”, arXiv, 2019. ↩
-
Holderrieth, Erives, “An Introduction to Flow Matching and Diffusion Models”, arXiv, 2025. ↩
-
Geng, Lu, Zu, Shechtman, Kolter, He, “Improved Mean Flows: On the Challenges of Fastforward Generative Models”, arXiv, 2025. ↩ ↩2 ↩3 ↩4
-
Sabour, Fidler, Kreis, “Align Your Flow: Scaling Continuous-Time Flow Map Distillation”, Neural Information Processing Systems, 2025. ↩ ↩2 ↩3 ↩4 ↩5
-
Tong, Ma, Xie, Jaakkola, “Flow Map Distillation Without Data”, arXiv, 2025. ↩ ↩2 ↩3
-
Gu, Zhai, Zhang, Liu, Susskind, “BOOT: Data-free Distillation of Denoising Diffusion Models with Bootstrapping”, arXiv, 2023. ↩
-
Tee, Zhang, Yoon, Gowda, Kim, Yoo, “Physics Informed Distillation for Diffusion Models”, Transactions on Machine Learning Research, 2024. ↩ ↩2 ↩3
-
Karras, Aittala, Kynkäänniemi, Lehtinen, Aila, Laine, “Guiding a Diffusion Model with a Bad Version of Itself”, Neural Information Processing Systems, 2024. ↩ ↩2
-
Luo, Yuan, Liu, “SoFlow: Solution Flow Models for One-Step Generative Modeling”, International Conference on Learning Representations, 2026. ↩ ↩2
-
Peng, Zhu, Liu, Wu, Li, Sun, Wu, “FACM: Flow-Anchored Consistency Models”, arXiv, 2025. ↩ ↩2 ↩3
-
Zhang, Siarohin, Menapace, Vasilkovsky, Tulyakov, Qu, Skorokhodov, “AlphaFlow: Understanding and Improving MeanFlow Models”, International Conference on Learning Representations, 2026. ↩
-
Lee, Yu, Shin, “Decoupled MeanFlow: Turning Flow Models into Flow Maps for Accelerated Sampling”, International Conference on Learning Representations, 2026. ↩ ↩2
-
Zhang, Tan, Nguyen, Dao, Han, He, Zhang, Mao, Metaxas, Pavlovic, “Overcoming the Curvature Bottleneck in MeanFlow”, arXiv, 2025. ↩
-
Lu, Lu, Sun, Zhao, Jiang, Wang, Li, Geng, He, “One-step Latent-free Image Generation with Pixel Mean Flows”, arXiv, 2026. ↩ ↩2 ↩3
-
Frans, Hafner, Levine, Abbeel, “One Step Diffusion via Shortcut Models”, International Conference on Learning Representations, 2025. ↩ ↩2
-
Salimans, Ho, “Progressive Distillation for Fast Sampling of Diffusion Models”, International Conference on Learning Representations, 2022. ↩
-
Guo, Wang, Yuan, Cao, Chen, Chen, Huo, Zhang, Wang, Liu, Wang, “SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling”, arXiv, 2025. ↩ ↩2 ↩3
-
Song, Dhariwal, “Improved Techniques for Training Consistency Models”, International Conference on Learning Representations, 2024. ↩ ↩2
-
Geng, Pokle, Luo, Lin, Kolter, “Consistency Model Made Easy”, International Conference on Learning Representations, 2025. ↩
-
Lu, Song, “Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models”, International Conference on Learning Representations, 2025. ↩
-
Kim, Lai, Liao, Murata, Takida, Uesaka, He, Mitsufuji, Ermon, “Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion”, International Conference on Learning Representations, 2024. ↩ ↩2 ↩3
-
Meng, Rombach, Gao, Kingma, Ermon, Ho, Salimans, “On Distillation of Guided Diffusion Models”, Computer Vision and Pattern Recognition, 2023. ↩
-
Chen, Jiang, Zheng, Chen, Su, Zhu, “Visual Generation Without Guidance”, International Conference on Machine Learning, 2025. ↩
-
Hu, Lai, Mitsufuji, Ermon, “CMT: Mid-Training for Efficient Learning of Consistency, Mean Flow, and Flow Map Models”, International Conference on Machine Learning, 2026. ↩
-
Li, He, “Back to Basics: Let Denoising Generative Models Denoise”, arXiv, 2025. ↩
-
Zhang, Isola, Efros, Shechtman, Wang, “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric”, Computer Vision and Pattern Recognition, 2018. ↩
-
Luo, Tan, Patil, Gu, von Platen, Passos, Huang, Li, Zhao, “LCM-LoRA: A Universal Stable-Diffusion Acceleration Module”, arXiv, 2023. ↩
-
Rombach, Blattmann, Lorenz, Esser, Ommer, “High-Resolution Image Synthesis With Latent Diffusion Models”, Computer Vision and Pattern Recognition, 2022. ↩
-
Rouard, Orsini, Roebel, Zeghidour, Défossez, “Continuous Audio Language Models”, International Conference on Learning Representations, 2026. ↩
-
Chung, Kim, Mccann, Klasky, Ye, “Diffusion Posterior Sampling for General Noisy Inverse Problems”, International Conference on Learning Representations, 2023. ↩
-
Bansal, Chu, Schwarzschild, Sengupta, Goldblum, Geiping, Goldstein, “Universal Guidance for Diffusion Models”, Computer Vision and Pattern Recognition, 2023. ↩
-
Wu, Trippe, Naesseth, Blei, Cunningham, “Practical and Asymptotically Exact Conditional Sampling in Diffusion Models”, Neural Information Processing Systems, 2023. ↩
-
Sabour, Albergo, Domingo-Enrich, Boffi, Fidler, Kreis, Vanden-Eijnden, “Test-time scaling of diffusions with flow maps”, arXiv, 2025. ↩ ↩2
-
Xu, Z hu, Li, He, Wang, Sun, Li, Qin, Wang, Liu, Zhang, “Consistency Model is an Effective Posterior Sample Approximation for Diffusion Inverse Solvers”, arXiv, 2024. ↩
-
Woo, Skreta, Park, Neklyudov, Ahn, “Riemannian MeanFlow”, arXiv, 2026. ↩ ↩2
-
Mammadov, Takao, Chen, Baptista, Mardani, Teh, Berner, “Variational Flow Maps: Make Some Noise for One-Step Conditional Generation”, arXiv, 2026. ↩
-
Potaptchik, Saravanan, Mammadov, Prat, Albergo, Teh, “Meta Flow Maps enable scalable reward alignment”, arXiv, 2026. ↩
-
Holderrieth, Chen, Eyring, Shah, Anantharaman, He, Akata, Jaakkola, Boffi, Simchowitz, “Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps”, arXiv, 2026. ↩
-
Roos, Davis, Eijkelboom, Bronstein, Welling, Ceylan, Ambrogioni, van de Meent, “Categorical Flow Maps”, arXiv, 2026. ↩
-
Lee, Yoo, Agarwal, Shah, Huang, Raghunathan, Hong, Boffi, Kim, “Flow Map Language Models: One-step Language Modeling via Continuous Denoising”, arXiv, 2026. ↩
-
Potaptchik, Yim, Saravanan, Holderrieth, Vanden-Eijnden, Albergo, “Discrete Flow Maps”, arXiv, 2026. ↩
-
Dieleman, Sartran, Roshannai, Savinov, Ganin, Richemond, Doucet, Strudel, Dyer, Durkan, Hawthorne, Leblond, Grathwohl, Adler, “Continuous diffusion for categorical data”, arXiv, 2022. ↩
-
Davis, Albergo, Boffi, Bronstein, Bose, “Generalised Flow Maps for Few-Step Generative Modelling on Riemannian Manifolds”, International Conference on Learning Representations, 2026. ↩
-
Rehman, Akhound-Sadegh, Gazizov, Bengio, Tong, “FALCON: Few-step Accurate Likelihoods for Continuous Flows”, arXiv, 2025. ↩
-
Ai, He, Gu, Salakhutdinov, Kolter, Boffi, Simchowitz, “Joint Distillation for Fast Likelihood Evaluation and Sampling in Flow-based Models”, International Conference on Learning Representations, 2026. ↩
-
Yin, Gharbi, Zhang, Shechtman, Durand, Freeman, Park, “One-step Diffusion with Distribution Matching Distillation”, arXiv, 2023. ↩
-
Zhou, Zheng, Wang, Yin, Huang, “Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation”, International Conference on Machine Learning, 2024. ↩
-
Salimans, Mensink, Heek, Hoogeboom, “Multistep Distillation of Diffusion Models via Moment Matching”, Neural Information Processing Systems, 2024. ↩
-
Zhou, Ermon, Song, “Inductive Moment Matching”, International Conference on Machine Learning, 2025. ↩
-
Sauer, Lorenz, Blattmann, Rombach, “Adversarial Diffusion Distillation”, arXiv, 2023. ↩
-
Lin, Yang, Lin, Chen, Fan, “Continuous Adversarial Flow Models”, arXiv, 2026. ↩
-
Yu, Qi, Li, Zhang, Zhang, Lin, Shechtman, Wang, Nitzan, “Self-Evaluation Unlocks Any-Step Text-to-Image Generation”, arXiv, 2025. ↩
-
Yang, Geng, Ju, Tian, Wang, “Representation Fréchet Loss for Visual Generation”, arXiv, 2026. ↩
-
Heusel, Ramsauer, Unterhiner, Nessler, Hochreiter, “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium”, Neural Information Processing Systems, 2017. ↩
-
Ioffe, “Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models”, Neural Information Processing Systems, 2017. ↩
-
Chen, Zhang, Tan, Guibas, Wetzstein, Bi, “pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation”, International Conference on Learning Representations, 2026. ↩
-
Deng, Li, Li, Du, He, “Generative Modeling via Drifting”, arXiv, 2026. ↩